Microsoft Research has developed a new way to feed knowledge into LLMs
Microsoft Research has developed a more efficient way to incorporate external knowledge into language models. The new system, called Knowledge Base-Augmented Language Models (KBLaM), takes a plug-and-play approach that doesn't require modifying existing models.
Unlike current approaches such as RAG or In-Context Learning, KBLaM doesn't use separate retrieval systems. Instead, it turns knowledge into vector pairs and weaves them directly into the model's architecture using what Microsoft calls "rectangular attention."
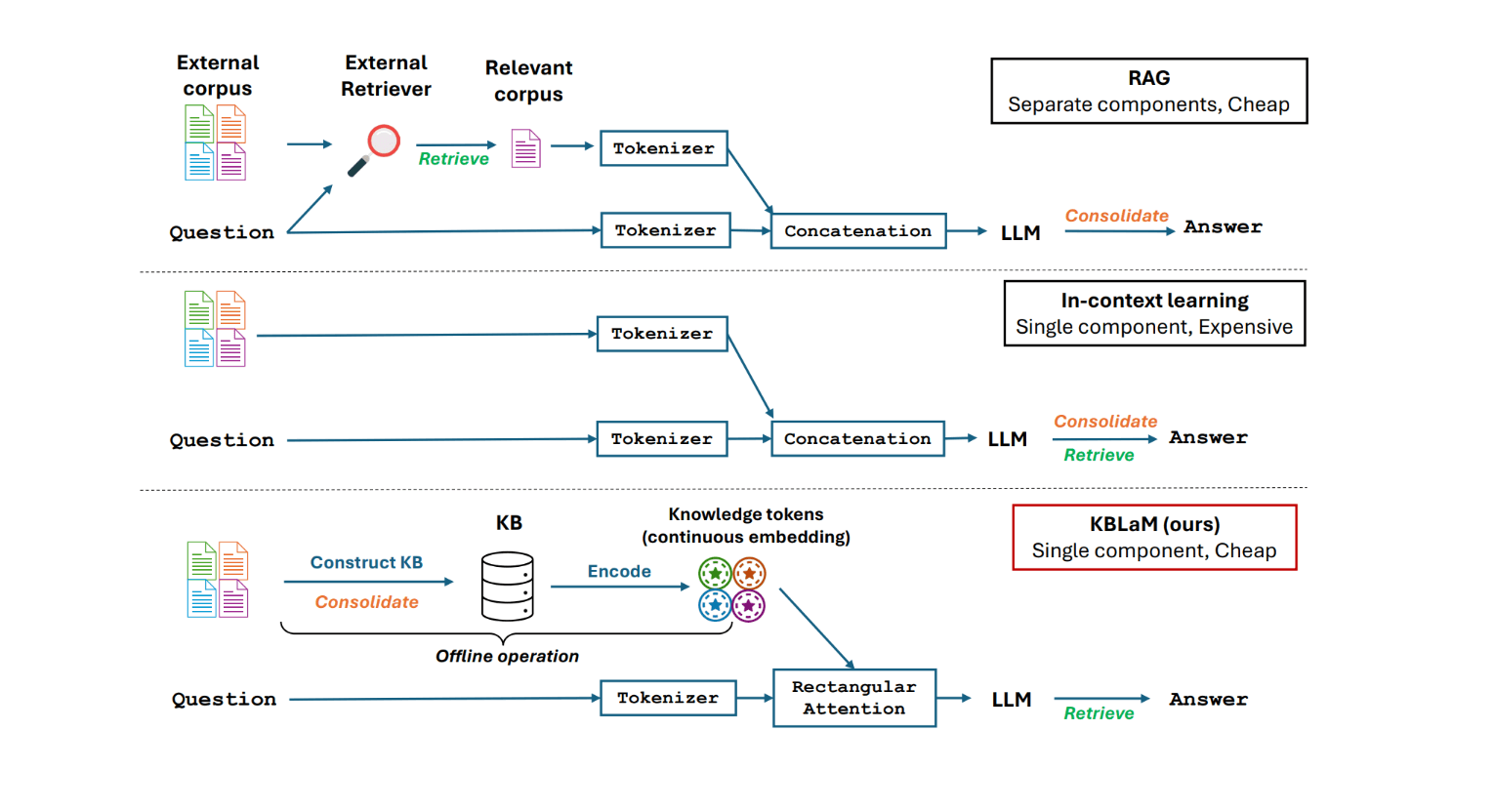
Current RAG systems face a quadratic scaling problem due to their self-attention mechanism - every token must interact with every other token. When 1,000 tokens from the knowledge base are inserted into the context, the model must process one million token pairs. With 10,000 tokens, that jumps to 100 million interactions.
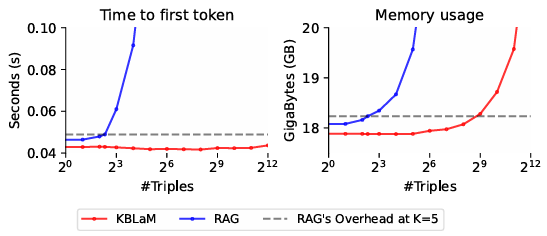
KBLaM sidesteps this issue: while the user's input can access all knowledge tokens, those knowledge tokens don't interact with each other or the input. This means that as the knowledge base grows, the required computational power increases only linearly. According to the researchers, a single GPU can handle more than 10,000 knowledge triples (about 200,000 tokens).
Opening up to developers
Tests show some promising results. Working with about 200 knowledge items, KBLaM is better than traditional models at avoiding hallucinations and refusing to answer questions for which it doesn't have information. It's also more transparent than in-context learning because it can link knowledge to specific tokens.
The code and datasets for KBLaM are now available on GitHub. The system works with several popular models, including Meta's Llama 3 and Microsoft's Phi-3, with plans to add support for Hugging Face Transformers. The researchers emphasize that KBLaM isn't ready for widespread use yet. While it handles straightforward question-answer scenarios well, it still needs work on more complex reasoning tasks.
LLMs struggle with an interesting paradox: their context windows keep getting bigger, letting them handle more information at once, but processing all that data reliably remains a challenge. As a result, RAG has become the go-to solution for feeding specific information into models with relative reliability, but KBLaM suggests that there may be a more efficient way forward.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.