
With WaveCoder and CodeOcean, Microsoft shows how generative AI can be used to get better training data.
Microsoft researchers have unveiled WaveCoder, a new programming language model that aims to outperform models of similar size with fewer training examples. The team has also developed CodeOcean, a curated dataset of 20,000 different code examples, to improve the fine-tuning of foundation models for programming applications.
According to the researchers, one of the biggest challenges in creating smaller, more efficient models for programming languages is balancing the size of the training dataset with the performance of the model. The CodeOcean dataset aims to overcome this challenge by providing maximum diversity in a limited number of examples. CodeOcean is based on CodeSearchNet, a massive code dataset with 2 million pairs of comments and code, which the team has reduced to a smaller but still diverse subset using embeddings and a BERT-based model.
CodeOcean uses a generator-discriminator framework for high-quality training data
To create training examples containing code and instructions, the researchers then used a generator discriminator framework to create instructions based on the raw code examples. First, GPT-4 was used to define tasks within specific scenario contexts. These tasks were then combined with an instruction and passed to GPT-3.5 to generate similar instructions for further examples. In this way, the team automatically generates a large amount of training data containing instructions and code, such as code tasks with natural language descriptions and solutions.
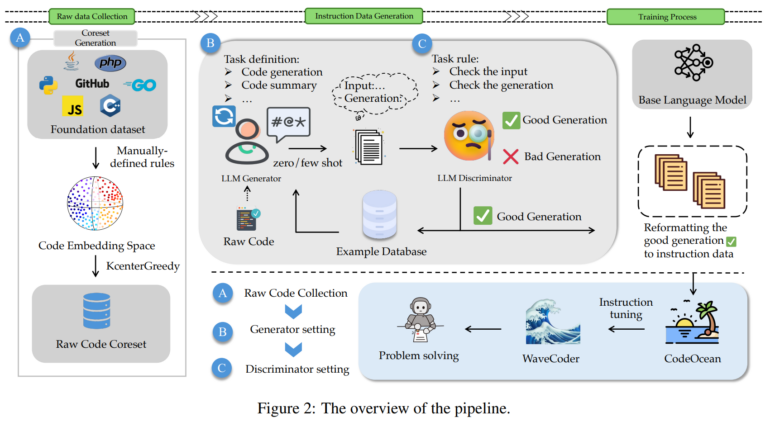
The data is then sent back to GPT-4, where it is evaluated according to defined criteria. Good examples are transferred to a sample database, which serves as a template for generating further training data. Through this iterative process, the team generated 20,000 high-quality examples covering four different categories of code tasks: code generation, code summarization, translation into another programming language, and code repair.
WaveCoder shows the importance of good data
The team trained WaveCoder on this dataset and compared it to WizardCoder, a model trained on about four times the amount of data. The team found that the difference in performance was small, suggesting that refined and diversified instruction data can significantly improve the efficiency of instruction tuning. WaveCoder also outperformed other open-source models on code summarization and repair tasks in nearly all programming languages.
The researchers also used CodeOcean to refine three programming language models: StarCoder-15B, CodeLLaMA (7B and 13B), and DeepseekCoder-6.7B. In three important programming benchmarks - HumanEval, MBPP and HumanEvalPack - all models showed significant improvements of up to 20 percent.
CodeOcean and WaveCoder are not yet available, but according to one of the researchers involved, will be published soon.




