Microsoft's SpreadsheetLLM can tackle huge scientific and financial spreadsheets

Microsoft researchers have developed SpreadsheetLLM, a method to optimize language models for analyzing spreadsheets.
The researchers explain that conventional spreadsheets are often too large and complex for AI models. SpreadsheetLLM solves this problem by converting the data into a more compact format, potentially making language models useful for many scientific and financial applications.
The approach reduces the amount of data by up to 96 percent without losing important information, according to the team. This allows AI systems to analyze very large spreadsheets, which was not possible before.
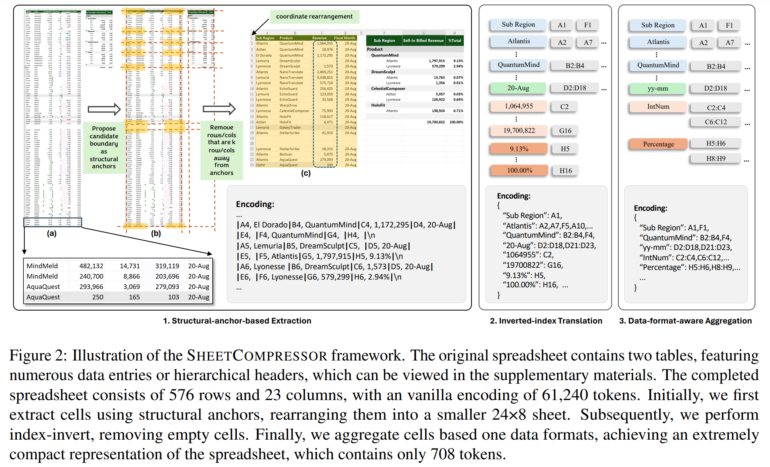
The new method is based on three main techniques:
- Structural Anchors: Identifies heterogeneous rows and columns at potential table boundaries, removes distant, homogeneous rows and columns and creates a condensed "skeleton" version of the spreadsheet for better layout insights.
- Inverted-Index Translation: Replaces traditional row-by-column serialization with a JSON-format inverted-index translation. Creates a dictionary indexing non-empty cell texts and merges addresses with identical text to optimize token usage while maintaining data integrity.
- Data Format Aggregation:Extracts number format strings and data types from adjacent numerical cells and clusters cells with similar formats or types together.
Using these techniques, the system captures the essential information of a spreadsheet without needing to store every single cell.
SpreadsheetLLM improves accuracy by up to 75 percent
The researchers tested their method with various AI models, including OpenAI's GPT-4 and open-source models like Llama 2. In the task of recognizing tables in spreadsheets, the system achieved an accuracy of 79 percent - an improvement of 13 percentage points over the previous best score.
The advantage of the new method was particularly evident with very large spreadsheets. For the largest files tested, accuracy improved by 75 percentage points compared to conventional techniques, as the token limits of the language models were no longer exceeded.
The researchers also developed a technique called "Chain of Spreadsheet" (CoS) to answer complex queries about spreadsheets. This divides the task into two steps: First, the system identifies the relevant table area, then it generates the answer. Using this method, the system achieved 74 percent accuracy on question-answering tasks related to spreadsheets.
The scientists acknowledge that their method still has limitations. Currently, formatting details such as background colors, which could provide additional information, are not considered. The researchers also see room for improvement in the semantic condensation of text cells.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.