Microsoft's VibeVoice is a new AI podcast model that might generate spontaneous singing

Microsoft's VibeVoice system can generate up to 90 minutes of conversation involving as many as four speakers.
Previous speech generation models typically struggled with longer outputs or group conversations. According to Microsoft's technical report, VibeVoice is the first to handle hour-and-a-half-long group conversations in a single run.
The key is a new audio compression method. Microsoft researchers developed a Speech Tokenizer that's 80 times more efficient than earlier approaches, so the system can generate and store long conversations without running into memory issues.
Singing, emotions, and language switching
In the demos, some samples include background music, but the technical paper makes clear that the model itself is focused solely on speech synthesis and does not process background noise, music, or other sound effects. So far, VibeVoice supports English and Chinese, with some cross-language features.
Spontaneous Singing:
Emotions:
Mandarin to English:
One example of VibeVoice's long-form capabilities is a 93-minute conversation about climate change featuring four different speakers. The system produces realistic discussion dynamics, disagreements, and emotional reactions, along with natural pauses, smooth speaker transitions, and context-dependent intonation.
VibeVoice splits processing into two parts: one handles sound quality and voice, the other manages meaning and conversation flow. It uses a pre-trained Qwen2.5 speech model (1.5 or 7 billion parameters) to control dialog, while a four-layer diffusion head with about 123 million parameters generates the audio.
Two tokenizers work in parallel. The Acoustic Tokenizer (a variational autoencoder) compresses 24 kHz audio down to 7.5 frames per second. The Semantic Tokenizer, built on a similar architecture, focuses on speech recognition.
Users provide text scripts and voice samples for each speaker. The system builds the audio step by step, accounting for context, speaker changes, and pauses. The larger 7-billion-parameter model sounds more expressive but needs more computing power.
VibeVoice isn't built for real-time use like live translation, and Microsoft hasn't shared processing speed or hardware requirements.
Benchmarking against Gemini and ElevenLabs
In tests with 24 human evaluators, VibeVoice was rated higher than Google's Gemini 2.5 Pro and ElevenLabs V3 for naturalness, realism, and expressiveness. The 7-billion-parameter model received the best scores across all categories.
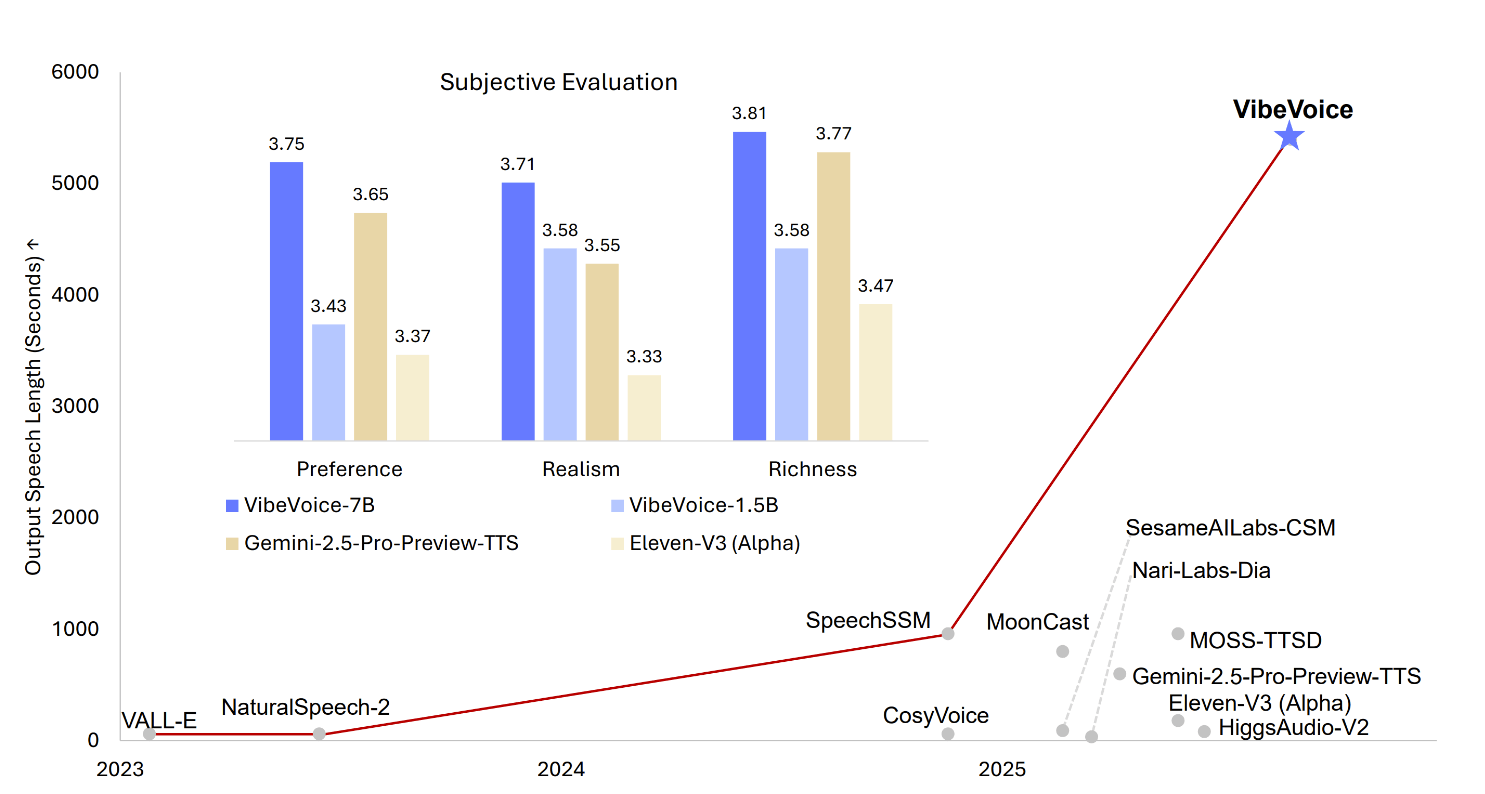
Automatic voice quality checks showed a transcription error rate of 1.29 percent for VibeVoice, compared to 1.73 percent for Gemini and 2.39 percent for ElevenLabs. The system was tested on eight long conversational transcripts, totaling around an hour. VibeVoice was able to generate natural, interruption-free speech throughout.
Built-in safeguards
Microsoft warns that high-quality synthetic speech raises risks like deepfakes and disinformation. Each VibeVoice audio file includes both an audible indicator and a digital watermark to mark its AI origin and enable tracking.
VibeVoice is open source, with weights available on Hugging Face. The model is intended for research only, not commercial use.
Microsoft first explored nuanced speech synthesis in March 2024 with NaturalSpeech 3, which separates prosody and timbre from content. OpenAI later updated ChatGPT's Advanced Voice Mode for more natural, emotionally nuanced speech and continuous multilingual translation.
Meanwhile, Resemble AI has shown with its open-source Chatterbox model that expressive voices can now be generated locally and nearly in real time with just 5 to 6 GB of VRAM.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.