MPT-7B: The best open-source LLM available for commercial use

MosaicML releases the best open-source language model yet, licensed for commercial use. One variant can even handle entire books.
MosaicML's MPT-7B is a large language model with nearly 7 billion parameters, which the team trained on its own dataset of nearly a trillion tokens.
MosaicML followed the training regimen of Meta's LLaMA model. The training cost nearly $200,000 and took 9.5 days using the MosaicML platform.
MosaicML MPT-7B is the best open-source model yet
According to MosaicML, MPT-7B matches the performance of Meta's 7-billion-parameter LLaMA model, making it the first open-source model to reach that level, ahead of OpenLLaMA.
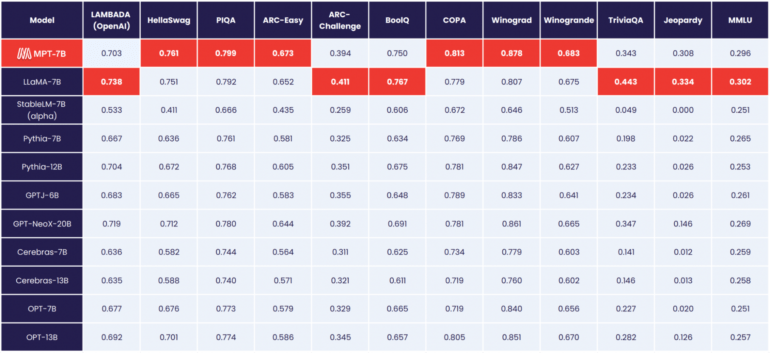
Unlike Meta's models, however, MPT-7B is licensed for commercial use.
In addition to the "MPT-7B Base" model, MosaicML also releases three variants: MPT-7B-StoryWriter-65k+, MPT-7B-Instruct and MPT-7B-Chat.
MosaicML releases language model with 65,000 tokens context
MPT-7B-Instruct is a model for following instructions, and the Chat model is a chatbot variant in the style of Alpaca or Vicuna.
With MPT-7B-StoryWriter-65k+, MosaicML also releases a model that is able to read and write stories with very long context lengths. For this purpose, MPT-7B was fine-tuned with a context length of 65,000 tokens using a subset of the books3 dataset. The largest GPT-4 variant of OpenAI is able to handle 32,000 tokens.
According to MosiacML, the model can scale beyond 65,000 tokens with some optimizations, and the team has demonstrated up to 84,000 tokens on a single node using Nvidia A100-80GB GPUs. But even with 65,000 tokens, it was possible to read entire novels and write an epilogue.

All MPT-7B models are available on GitHub.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.