An experiment to find out how close NeRFs are to replacing certain types of traditional video production. A six-figure budget, 30-day production, and the world's biggest MoCo crane vs a guy with a smartphone, some open-source libraries, and a consumer GPU.
A few years ago, I was the creative director on a series of films for the launch of the 2019 Acura RDX. We shot a series of matching 360 fly-around videos of the car in three different environments, and I had the pleasure and bucket-list-item-filling experience of shooting the films with the Titan Motion Control Rig, a rig that still in 2023 has the largest range of motion of any MoCo rig in the world. In addition to capturing the fly-around videos at very high precision, the rig also allowed us to lower the camera into the car, an important feature of the film because the car launched with a class-leading moonroof.

Great production, with excellent crew both on set and in post, and the resulting video was so good that a senior client suggested we should do this for all their cars without the moonroof part. Unfortunately, this turned out to not be feasible, because the production had a six-figure production and post-production budget. We had a 10-hour shoot day per location and about 4 weeks of post-production. Granted, a lot of this had to do with the complexity of the moonroof, but even without that, the production realities wouldn’t work out.
NeRF versus Motion Control Rig
But in 2023 we’re at a place where we might be able to pull this off at a much lower cost and much faster, thanks to modern implementations of NeRFs, a machine-learning framework for presenting real-world scenes as Neural Radiance Fields, first introduced by Matthew Tancik et. al in 2020 as a research paper. At a high level NeRFs are virtual 3D representations of real-world scenes. They’re created by capturing a series of photos of that real-world scene and then running these photos through a series of algorithms that calculate where they belong in a 3D space. The photos and positional data are then used to train the NeRF. Once the NeRF has been trained, it can be visualized in a 3D environment that simulates the light (or radiance) in the scene from every conceivable angle.
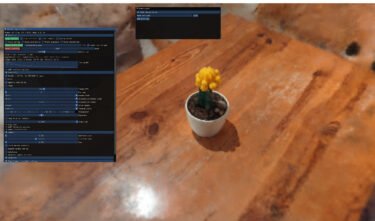
The screenshot below demonstrates this in action, with roughly ~300 photos extracted from a short video I show, walking three times around my car holding my phone camera at three different heights. In this scene, I can move my viewport wherever I please, as long as there are pixels in the ~300 photos covering that area.

As always it takes a while for research papers to see real-world applications, and the tools available are not yet meant for production, but the output is already very promising. I’ve used Nerfstudio for this project, and that’s where the screenshot is from. It is an excellent open-source project by a fine group of researchers, but there are other implementations available, including Instant-ngp from NVidia Labs.
Video: Martin Pagh Ludvigsen
On the left is one of the three finished videos we produced in 2018. On the right is a video I rendered from a NeRF I created a few weeks ago. I’ve already mentioned how much time and money was spent on the one on the left. The one on the right took 2.5 hours of production with a crew of me: About 1.5 hours of that was driving from my home to a location with snow and back, 30 minutes was spent setting up and capturing the content for the NeRF, and 30 minutes was spent digging my car out from the 18 inches of snow I got my car stuck in to get the footage.
But by far the biggest time-saver is in post-production. There is no giant motion control crane we need to paint out, light changes we need to match because the sun moved across the sky during the shoot, or shadows on the ground we need to recreate. On my consumer-grade GPU it took about 1 hour to train the NeRF model. I spent 45 minutes rigging the scene, and another hour rendering the videos. So, the total time spent on production and post is less than a day, including transportation and shoveling snow.

NeRFs allow for a perfect loop
Now, the video on the right is far from perfect; You can hardly make out the badges, lots of details are missing in the front grills and the sheet metal has lots of compression artifacts and lines that go missing. But keep in mind I shot this content on my smartphone while it was snowing, I didn’t even clean my car for the shoot, and I did no pre-processing to the source images or post-processing of the video. There are also “missing” parts of the ground and sky because I didn’t capture those areas in my walk around the car.
While the car on the left looks really good, the video still has lots of tiny issues, and two big ones:
1) It doesn’t loop perfectly. The reason is that it would be too hard to create a camera motion path that would both loop perfectly and allow us to create the many different versions of the video we needed. That’s not a problem with NeRFs, where the camera is created, placed, and controlled mathematically in post-production. That’s why the loop on the right is perfect. Even with the best motion control gear, that kind of perfect loop is hard to achieve.
2) It has that same motion-smoothy, soap opera look that you see on your parent’s TV set. That’s because we had to do frame interpolation in post to get the videos to the exact right lengths we needed. When you do a practical shoot, you only get the frames you shoot and finish in post, and that’s going to be limited by the time and budget you have. With NeRFs that’s not the case, because your output video is rendered from a virtual scene, and the length of the video isn’t in any way restrained by the available frames.
Video: Martin Pagh Ludvigsen
This means it’s almost trivial to create multiple different versions of the video at different aspect ratios, and the results will never suffer from the same issues as the practical video. That’s what I’ve done in the collage above, which also includes two of the notoriously difficult 9:16 videos - I gave the camera a slightly wider FOV and made a much more dynamic path instead of worrying about the usual challenges of converting a 16:9 video to 9:16. And I made one exactly 15 seconds and the other 7.5 seconds, because that’s as simple as typing in a number and hitting render. There’s your 1:1 (or 4:5) for the feed, 9:16 for story formats and 16:9 for the portfolio. In fact, since it’s for the portfolio, I might as well go ahead and create an even more useless, but very pretty 2.4:1 anamorphic version.
Video: Martin Pagh Ludvigsen
NeRFs are incredibly powerful
I’m positive the visual quality will improve, and for some of my next experiments, I want to try better cameras and lenses, pre-processing the images to clean up any flaws, maybe washing my car and possibly increasing the resolution of the source material by shooting 8k.
But the biggest drawback is that there is no action in the scene - a NeRF is a frozen moment in time, in fact, you want to make sure there are no changes in the scene while you’re capturing it, or the NeRF will be imperfect. If you want to capture action, you need a full light field camera system, like the now-failed Lytro system, a system that famously stored 400 GB of data for every second of capture. But of course action can be added as CGI instead, and there is already research on how to bring action into NeRFs.
NeRFs can be exported in formats such as point clouds that can be imported in 3D CGI software like Blender or Maya, or real-time 3D platforms like Unreal Engine or Unity3D where it’s likely to complement or possibly replace photogrammetry as the preferred method for importing real objects and scenes into 3D software.
But even by themselves, NeRFs are incredibly powerful, and I believe these experiments demonstrate they’re very close to being ready for the production of simple videos of real-life objects and scenes for social media.
Find out more about Martin on his Website.