Stable Diffusion meets Reinforcement Learning - demonstrating how to effectively train generative AI models for images on downstream tasks.
Diffusion models are now standard in image synthesis and have applications in artificial protein synthesis, where they can aid in drug design. The diffusion process converts random noise into a pattern, such as an image or protein structure.
During training, diffusion models learn to reconstruct content incrementally from training data. Researchers are now trying to intervene in this process using reinforcement learning to fine-tune generative AI models to achieve specific goals, such as improving the aesthetic quality of images. This is inspired by the fine-tuning of large language models, like OpenAI's ChatGPT.
Reinforcement learning for more aesthetic images?
A new paper from Berkeley Scientific Intelligence Research examines the effectiveness of reinforcement learning using Denoising Diffusion Policy Optimization (DDPO) for fine-tuning to different goals.
The team trains Stable Diffusion on four tasks:
- Compressibility: How easy is the image to compress using the JPEG algorithm? The reward is the negative file size of the image (in kB) when saved as a JPEG.
- Incompressibility: How hard is the image to compress using the JPEG algorithm? The reward is the positive file size of the image (in kB) when saved as a JPEG.
- Aesthetic Quality: How aesthetically appealing is the image to the human eye? The reward is the output of the LAION aesthetic predictor, which is a neural network trained on human preferences.
- Prompt-Image Alignment: How well does the image represent what was asked for in the prompt? This one is a bit more complicated: we feed the image into LLaVA, ask it to describe the image, and then compute the similarity between that description and the original prompt using BERTScore.
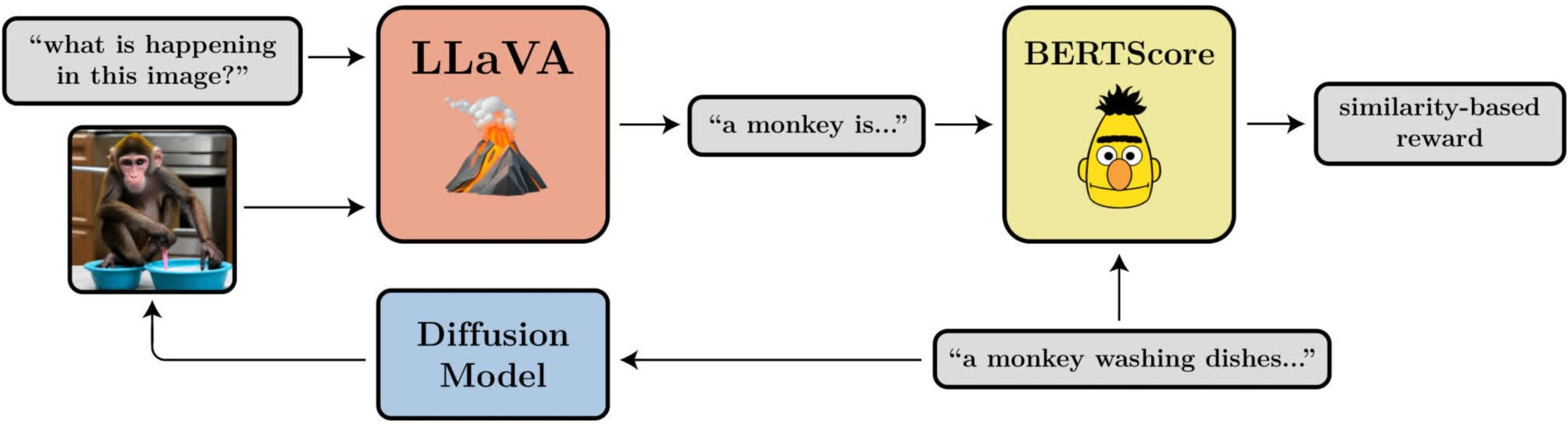
In their tests, the team showed that DDPO can be used effectively to optimize the four tasks. In addition, they showed some generalizability: the optimizations for aesthetic quality or prompt image alignment, for example, were performed for 45 common animal species, but were also transferable to other animal species or the representation of inanimate objects.
Video: BAIR
New method does not require training data
As is common in reinforcement learning, DDPO also exhibits the phenomenon of reward overoptimization: the model destroys all meaningful image content in all tasks after a certain point in order to maximize reward. This problem needs to be investigated in further work.

Still, the method is promising: "What we’ve found is a way to effectively train diffusion models in a way that goes beyond pattern-matching — and without necessarily requiring any training data. The possibilities are limited only by the quality and creativity of your reward function."
More information and examples are available on the BAIR project page on DDPO.