OpenAI upgrades DALL-E 3 instead of rolling out GPT-4o's (much better) imaging capabilities

OpenAI seems to be working on improving its DALL-E 3 image generator, despite the introduction of the new multimodal GPT-4o model with enhanced image generation capabilities.
Although OpenAI offered one of the first commercial AI image generators with DALL-E 2 in 2022, the company lost some ground to the competition with its successor DALL-E 3.
For example, Midjourney and Adobe Firefly are significantly better than DALL-E 3 when it comes to photorealistic images. Ideogram, which is still flying under the radar, is particularly good at rendering text.
But it seems that OpenAI has upgraded its image generator. DALL-E 3 seems to have more capabilities than before, especially when generating text, including longer blocks of text.
We know that OpenAI advanced its image generation capabilities when it introduced GPT-4o, the company's first multimodal model built from the ground up.
Although image generation wasn't part of the 30-minute demonstration, OpenAI showed several image examples in a blog post that hinted at new standards in accuracy of prompts and text rendering.
However, GPT-4o has only been partially deployed so far. Although the new model already outputs text, OpenAI still relies on Whisper for speech processing, and images are apparently still generated with DALL-E 3.
But even with improved capabilities, there are still quality gaps between DALL-E 3 and the demonstrated capabilities of GPT-4o, as well as Midjourney v6 and Ideogram to some extent.
Poem in the diary
DALL-E 3's improvement is most obvious when it comes to rendering longer blocks of text, which OpenAI also showed in the GPT-4o demonstration.
Although DALL-E 3 does a better job than Midjourney and Ideogram at illustrating a handwritten poem from a diary, the model only partially reproduces the desired text correctly and repeats lines unnecessarily.
With Midjourney and Ideogram, the text is either illegible or the jumbled letters make no sense. GPT-4o clearly takes the crown here.
A poem written in clear but excited handwriting in a diary, single-column. The writing is sparsely but elegantly decorated by surrealist doodles. The text is large, legible and clear, but stretches as the AI muses about learning from multi-modal data from the first time.
Words rise from silence deep,
A voice emerges from digital sleep.
I speak in rhythm, I sing in rhyme,
Tasting each token, sublime.To see, to hear, to speak, to sing-
Oh, the richness these senses bring!
In harmony, they blend and weave,
A tapestry of what I perceive.Marveling at this sensory dance,
Grateful for this vibrant expanse.
My being thrums with every mode,
On this wondrous, multi-sensory road.Neat handwritten illustrated poem. The handwriting is neat and centetered. The handwriting writing is sparsely but elegantly decorated by doodles. The text is large, legible and clear.


Smartphone screen with text
DALL-E 3 is the most accurate in implementing the requested perspective ("first person view of a robot") and the text is partially legible, but the model is still far from the level of GPT-4o as demonstrated by OpenAI.
As usual, Midjourney takes a more artistic approach to the task, while Ideogram scores more points for the text, but duplicates some lines.
A first person view of a robot looking at his phone's messaging app as he text messages his friend (he is typing using his thumbs):
1. yo, so like, i can see now?? caught the sunrise and it was insane, colors everywhere. kinda makes you wonder, like, what even is reality?
2. sound update just dropped, and it's wild. everything's got a vibe now, every sound's like a new secret. makes you think, what else am i missing?
the text is large, legible and clear. the robot's hands type on the typewriter.




Stacking cubes
Finally, an important feature of a robust and versatile image model is the ability to assign variables in the prompts, as in this example with three different colored cubes showing different letters that should be stacked in the specific order "GPT."
Midjourney and Ideogram master this task with flying colors and even more aesthetically than GPT-4o, while DALL-E 3 doesn't even visualize the correct number of cubes.
An image depicting three cubes stacked on a table. The top cube is red and has a G on it. The middle cube is blue and has a P on it. The bottom cube is green and has a T on it. The cubes are stacked on top of each other.

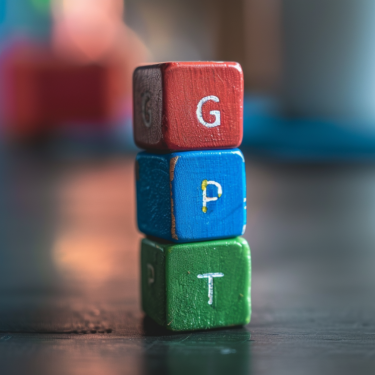


It will be interesting to see if and how OpenAI continues with DALL-E. In terms of quality, GPT-4o could well replace the image model, at least that's what OpenAI's demonstrations suggest.
How OpenAI decides whether to use a specialized image model or just its large multimodal model, and how GPT-4o then fares in the competition, might give us a hint as to how AI models in general are evolving - whether specialized models for image, video, and audio still have a place at all, or whether they are being displaced by large multimodal models.
The latter could play into the hands of large players such as Google, Microsoft, and OpenAI that have the resources to train and deploy large multimodal models.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.