OpenAI's new 'o1' model thinks longer to give smarter answers
Update –
- Added Jim Fan's statement
OpenAI has finally revealed details about its "Strawberry" project: a new AI model called o1. This model is designed to spend more time processing questions, aiming to set a new standard for AI logic. While not superior in all tasks, o1 is meant to create a new scaling horizon through increased compute.
OpenAI describes o1 as a "significant advancement" and a "new level of AI capability." The model has been trained using reinforcement learning to go through an internal "thought process" before answering.
Noam Brown, co-developer of the model, explains: "OpenAI o1 is trained with RL to 'think' before responding via a private chain of thought. The longer it thinks, the better it does on reasoning tasks."
This corresponds to the assumptions made beforehand about Project Strawberry. According to Brown, this opens up a new dimension for scaling. "We're no longer bottlenecked by pretraining. We can now scale inference compute too," Brown says.
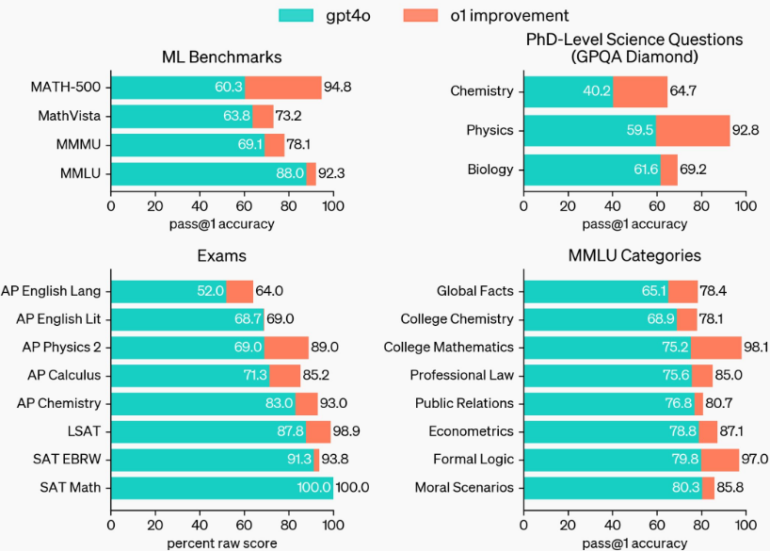
Best suited for logic-based tasks
Brown notes that o1 models don't outperform their predecessor GPT-4o in all areas. "Our o1 models aren't always better than GPT-4o. Many tasks don't need reasoning, and sometimes it's not worth it to wait for an o1 response vs a quick GPT-4o response."
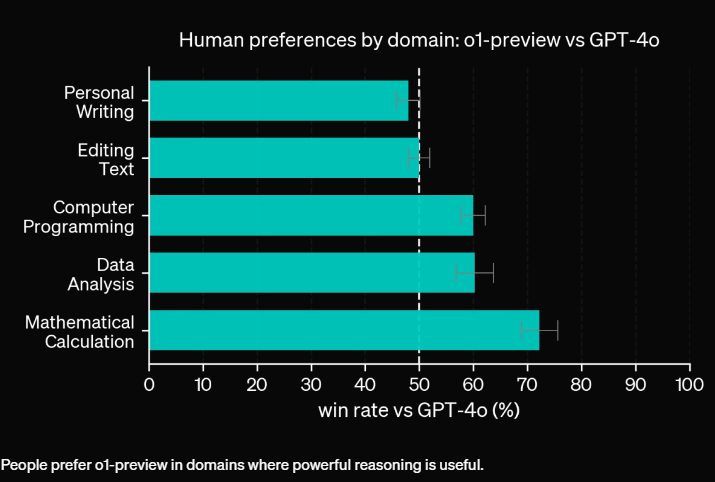
OpenAI has released o1-preview, a scaled-down version of o1, to identify its most suitable use cases and areas for improvement. Brown admits: "OpenAI o1-preview isn't perfect. It sometimes trips up even on tic-tac-toe. People will tweet failure cases. But on many popular examples people have used to show 'LLMs can't reason', o1-preview does much better, o1 does amazing, and we know how to scale it even further."
More computing power, better thinking
Currently, o1 only thinks for a few seconds before responding. In the future, however, OpenAI's vision is for the model to be able to think about an answer for hours, days, or even weeks.
While this increases the cost of inference, it is justified for groundbreaking applications such as developing new drugs or proving the Riemann Hypothesis. "AI can be more than chatbots," Brown says.
OpenAI has made the o1-preview and o1-mini models available via ChatGPT with immediate effect. The company is also publishing evaluation results for the as yet unfinished o1 model.
The aim is to show that this is not a one-off improvement, but a new paradigm for scaling AI models, says Brown. "We are only at the beginning."
O1-mini for STEM tasks
Alongside o1-preview, OpenAI introduced o1-mini, a more cost-effective version optimized for STEM applications. O1-mini achieves nearly the same performance as o1 in math and programming tasks but at a significantly lower cost. In a high school math competition, o1-mini scored 70 percent of o1's score, while o1-preview only reached 44.6 percent.
In programming challenges on the Codeforces platform, o1-mini performs almost as well as o1 (1673) and significantly better than o1-preview (1258) with an Elo score of 1650. In the HumanEval coding benchmark, the o1 models (92.4%) are only slightly ahead of GPT-4o (90.2%).
Because of its STEM focus, o1-mini's general knowledge in other areas is similar to smaller language models such as GPT-4o mini, according to OpenAI.
ChatGPT Plus and Team users can access o1-preview and o1-mini immediately, while Enterprise and Edu users will get access early next week. OpenAI plans to make o1-mini available to all free ChatGPT users but hasn't set a release date.
In the API, o1-preview costs $15 per 1 million input tokens and $60 per 1 million output tokens. GPT-4o is significantly cheaper at $5 per 1 million input tokens and $15 per 1 million output tokens. O1-mini is available for Tier 5 API users and is 80 percent cheaper than o1-preview, OpenAI says.
Nvidia researcher: OpenAI's new Strawberry model shifts compute from training to inference
Jim Fan, an AI researcher at Nvidia, has provided one of the first expert assessments of OpenAI's new model from outside the company. In a LinkedIn post, Fan states that o1 brings the inference scaling paradigm, previously discussed mainly in research, into production.
According to Fan, models for logical reasoning don't need to be enormous. Many parameters primarily store facts to perform well on benchmarks like knowledge tests. It's possible to separate logic and knowledge into a small "reasoning core" that knows how to call tools like browsers and code verifiers, potentially reducing pre-training compute requirements.
Instead, Strawberry shifts much of the compute to inference. Fan explains that language models are text-based simulators. By playing out many possible strategies and scenarios, the model eventually converges on good solutions. Fan suggests OpenAI has likely understood the inference scaling law for some time, while the scientific community is only now catching up.

However, Fan notes that productizing o1 is far more challenging than achieving top academic benchmarks. For real-world logic problems, decisions must be made about when to stop searching, what reward functions and success criteria to use, and when to incorporate tools such as code interpreters. The computational cost of these CPU processes must also be considered.
Fan believes that Strawberry could become a data flywheel. When answers are correct, the entire search trace becomes a mini-dataset of training examples with positive and negative rewards, potentially improving the "reasoning core" for future GPT versions.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.