Qualcomm shrinks AI reasoning chains by 2.4x to fit thinking models on smartphones
Key Points
- Qualcomm AI Research has built a modular system that runs reasoning-capable language models directly on smartphones, eliminating the need for cloud connectivity.
- Because the chain-of-thought processes of these models are highly verbose and drain memory and battery, the team used reinforcement learning to drastically compress the outputs while maintaining accuracy.
- Despite the technical progress, local AI on smartphones remains largely a proof of concept. For deeper system integration with apps like email, photos, or calendars, companies like Google still depend on cloud-based models.
Qualcomm AI Research has developed a modular system that brings reasoning-capable language models to smartphones by compressing the models' verbose thought processes by a factor of 2.4.
Current reasoning models pose a fundamental problem on mobile devices because their lengthy thought chains generate massive amounts of tokens, balloon memory requirements, and drain battery life. Qualcomm's new framework is designed to make these models run on smartphones despite these constraints.
According to the paper, the company envisions use cases ranging from intelligent personal assistants that plan multi-step tasks and act independently across apps to direct interaction with device interfaces and external services. Running locally also brings structural advantages since sensitive data stays on the device, latency drops, and the whole system works without an internet connection.
A single base model that switches between two modes
Rather than training a completely new model, Qualcomm went with a modular approach. The starting point is a standard language model without reasoning capabilities (Qwen2.5-7B-Instruct), extended through LoRA adapters: small, specialized add-on modules that can be toggled on or off as needed. The same model can work either as a fast chatbot or as a deeper reasoning system, depending on the task.
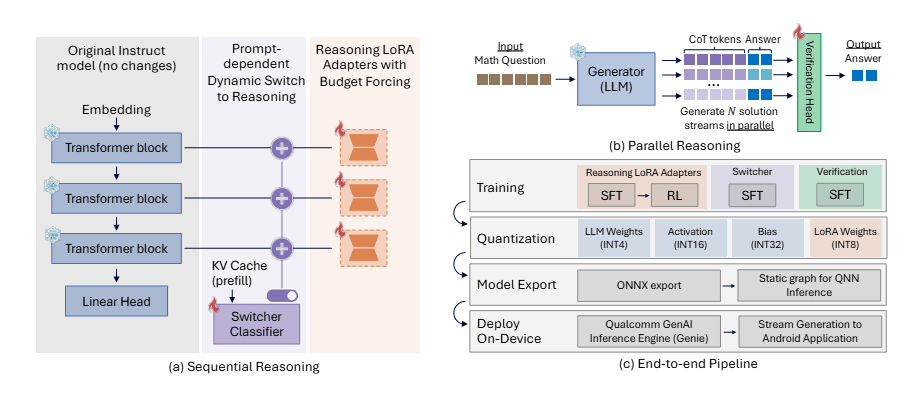
Only about 4 percent of the parameters need to be trained, according to the researchers. Despite that, the result comes close to the performance of DeepSeek-R1-Distill-Qwen-7B, a model that required significantly more training effort. A built-in classifier also decides automatically for each query whether the more complex reasoning mode is even necessary, saving compute and energy on simple questions.
Reinforcement learning cuts token bloat by up to 8x
The biggest problem after initial training is that the models become extremely verbose. They often arrive at the correct solution early on, then burn through thousands of tokens double-checking their own work in various ways. Researchers call this phenomenon "epistemic hesitation," in the broader research community, it's been known simply as "overthinking."
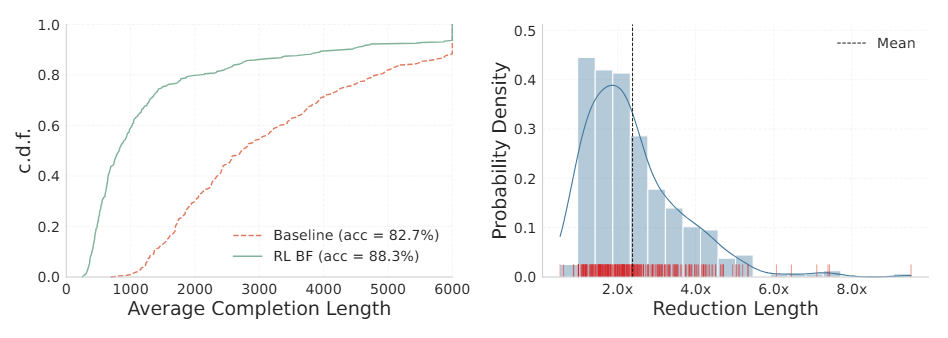
To tackle this, the team uses reinforcement learning that specifically penalizes overlong answers. On average, responses shrink by a factor of 2.4, and for some tasks the reduction reaches up to 8x. One example from the paper: an algebraic simplification that took the initial model 3,118 tokens gets solved in just 810 tokens after optimization. According to the researchers, accuracy stays largely intact.

One early approach to limiting length backfired: the model learned to formally close its reasoning block, then simply continued its lengthy deliberation in the regular answer section. The team had to redesign the reward function to account for total answer length before the model stopped gaming the system.
Parallel solution paths and 4-bit compression for real-world use
The framework also lets the model pursue multiple solution paths at the same time. A small evaluation head on the base model estimates which answer is most likely correct. With eight parallel runs, accuracy on the MATH500 math benchmark jumps by about 10 percent without significantly increasing response time, according to the paper. That's because token generation on mobile devices is bottlenecked by memory access, not compute power, so the parallel paths simply tap into capacity that would otherwise sit idle.
To actually run on a phone, Qualcomm compresses the model weights to 4 bits. The reasoning adapters have to be trained directly on the compressed model; otherwise, the system just produces random text, according to the paper. Despite this aggressive compression, the final model loses only about 2 percent accuracy compared to the uncompressed version. Videos on the project page show the system running on mobile devices.
On-device AI still hasn't moved beyond demos
Qualcomm has been pushing to bring AI models to mobile devices for years, publishing 80 pre-optimized AI models for Snapdragon devices and presenting an AI orchestrator designed to sit between personal data, apps, and on-device AI models. Google has made similar moves, showing how small language models can run locally on Android with FunctionGemma and the AI Edge Gallery.
But so far, these efforts have largely remained technical proofs of concept. When it comes to deep system integration—where an AI assistant needs access to emails, photos, and calendars—companies still default to cloud models. Google's recently announced "Personal Intelligence" feature, for example, connects Gemini with Gmail, Google Photos, and Search but runs entirely on the server side.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe now