Reasoning models like Claude Sonnet 4.5 are getting better at spotting security flaws
Anthropic sees growing potential for language models in cybersecurity. The company cites results from the CyberGym leaderboard: Claude Sonnet 4 uncovers new software vulnerabilities about 2 percent of the time, while Sonnet 4.5 increases that rate to 5 percent. In repeated tests, Sonnet 4.5 finds new vulnerabilities in more than a third of projects.
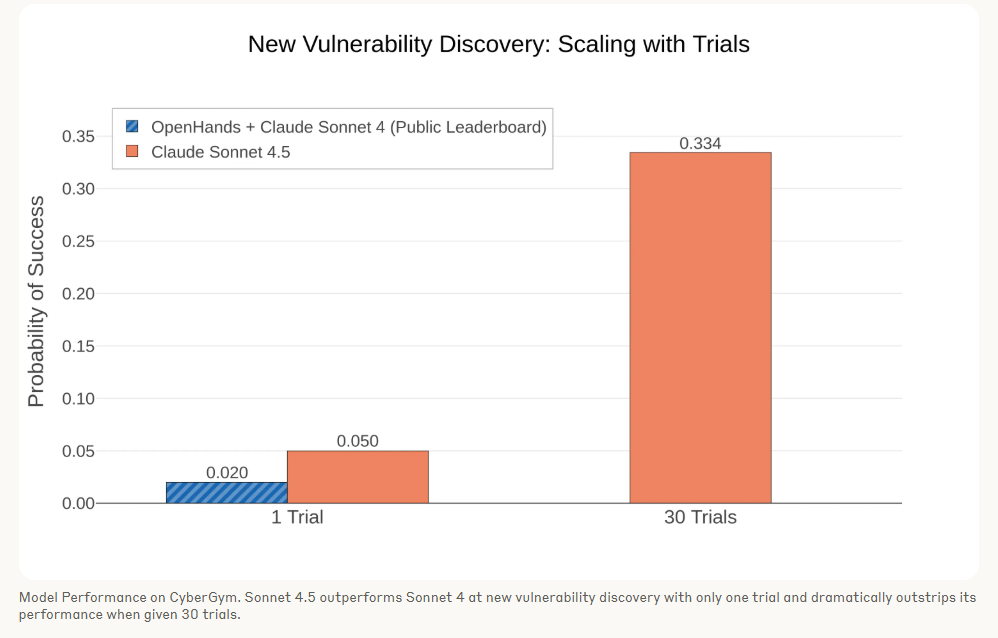
In a recent DARPA AI Cyber Challenge, Anthropic notes that teams used large language models like Claude "to build 'cyber reasoning systems' that examined millions of lines of code for vulnerabilities to patch." Anthropic calls this a possible "inflection point for AI’s impact on cybersecurity."
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.