Researchers discover three factors that make AI agents significantly smarter
Researchers from the National University of Singapore, Princeton, and the University of Illinois Urbana-Champaign have pinpointed three key factors that make AI agents smarter: data quality, algorithm design, and reasoning strategy.
Their work shows that a carefully trained 4-billion-parameter model can match or even beat competitors with up to 32 billion parameters.

Real data beats synthetic every time
The type of data used during training matters most. The researchers compared models trained on authentic learning trajectories against those trained on artificial data, where intermediate steps were replaced by tool outputs.
On AIME math benchmarks, a 4-billion-parameter model trained on real data achieved 29.79 percent accuracy. The same model trained on synthetic data scored under 10 percent.
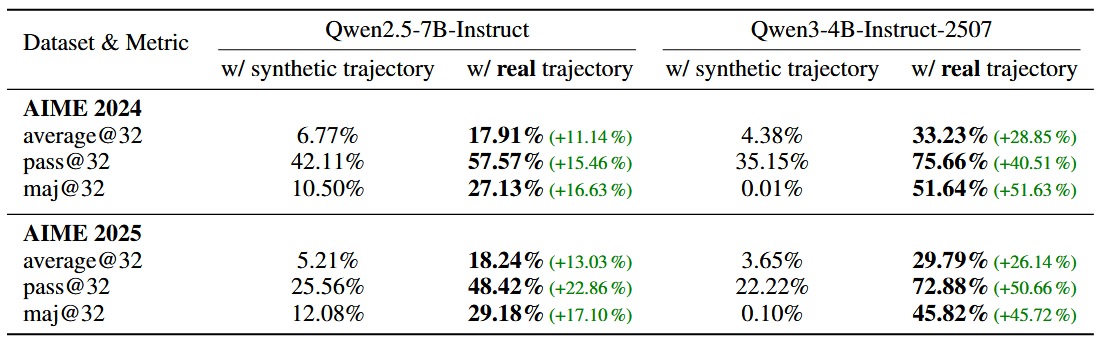
Real data captures the full reasoning workflow, including pre-tool analysis, guided execution, error correction, and self-reflection. Synthetic data can’t replicate these links, the researchers say.
Data diversity proved equally crucial. A mixed dataset of 30,000 examples from math, science, and programming accelerated learning dramatically. The AI hit 50 percent accuracy after just 150 training steps, while a math-only dataset needed 220 steps to reach the same benchmark.
Token-based scoring makes the difference
The second factor is how the learning process itself is structured. The team tested three algorithm variants, looking for the best way to optimize performance. The winner was a method called GRPO-TCR, which combines token-level scoring (grading each word chunk), broader clipping for more exploration, and a reward setup to discourage overly long answers.
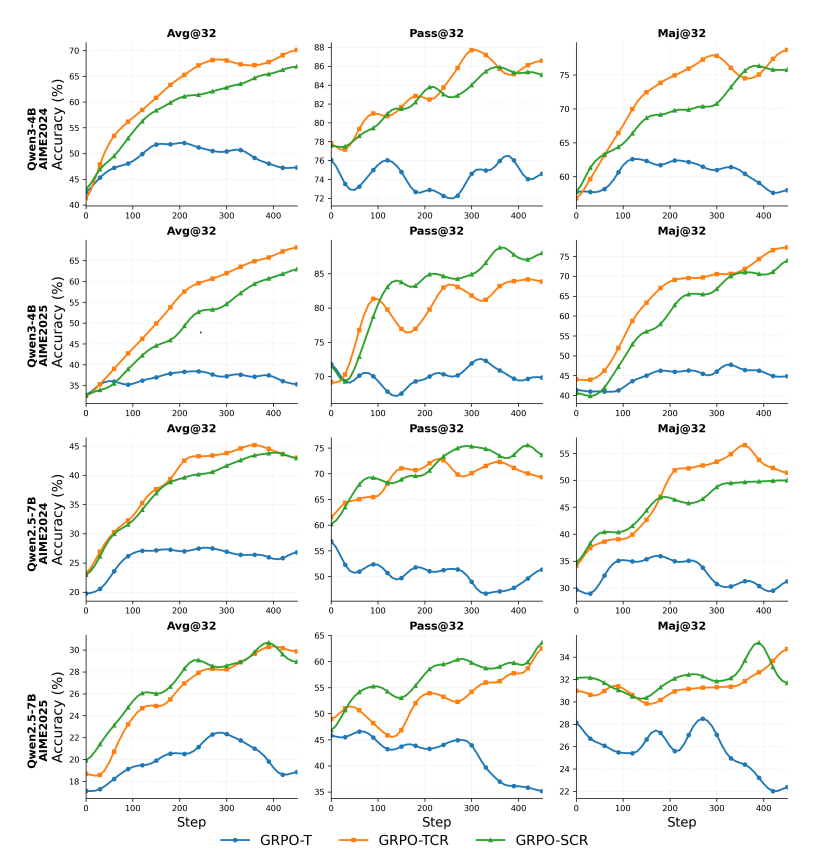
This optimized approach achieved 70.93 percent accuracy on one math benchmark and 68.13 percent on another. Token-based scoring proved particularly powerful, outperforming sentence-based methods by about 4 percent. Unlike traditional reinforcement learning, agents can improve both exploration and precision simultaneously through tool interactions.
Think more, act less
The third finding is about how the AI organizes its reasoning. The researchers found two main styles: reactive (short thinking, frequent tool use) and deliberative (longer thinking, fewer tool calls). Models using the deliberative strategy consistently achieved over 70 percent success rates in tool use. Reactive models performed poorly, as their rapid-fire tool calls were often ineffective or wrong. Quality trumps quantity every time.
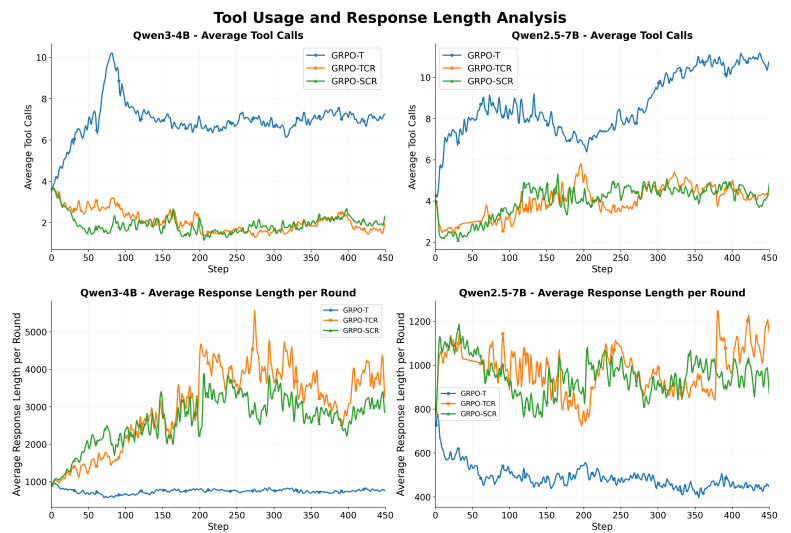
Interestingly, current long-chain-of-thought models struggle with tool integration. Despite being optimized for extended thinking, they tend to avoid tool calls entirely, relying only on internal reasoning processes.
Small but mighty
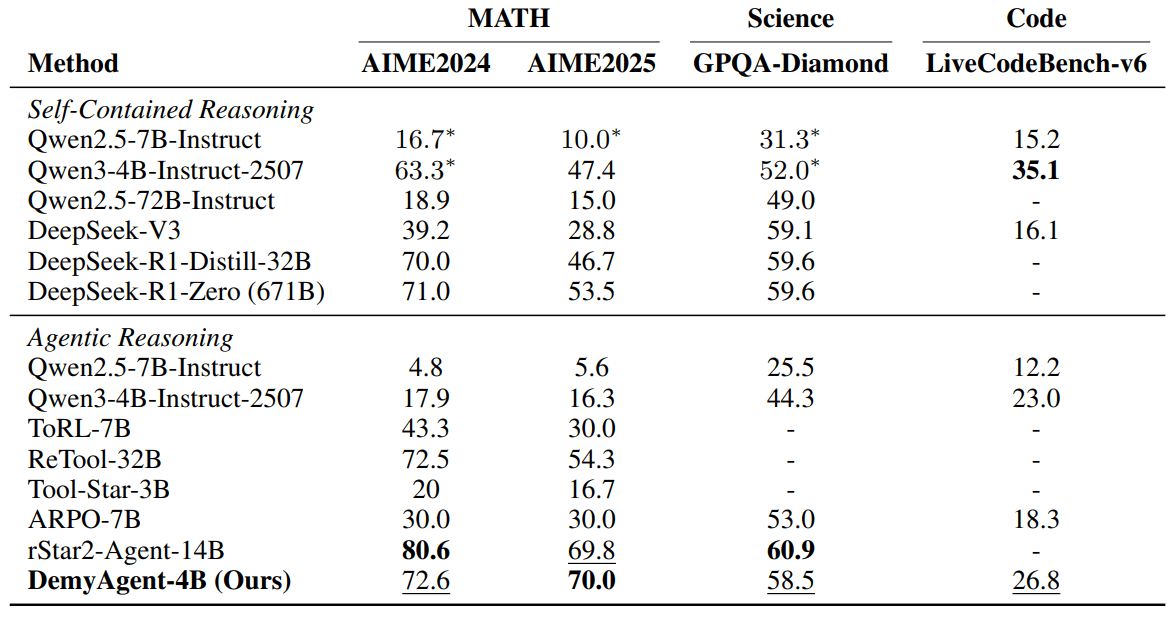
Applying these insights, the researchers built DemyAgent-4B with just 4 billion parameters. The results speak for themselves: 72.6 percent on AIME2024, 70 percent on AIME2025, 58.5 percent on GPQA-Diamond science tests, and 26.8 percent on LiveCodeBench-v6 programming benchmarks. This performance places it firmly among competitors with 14 to 32 billion parameters, proving that smart training beats brute force.
The researchers have released their training data and model weights for others to use and build on.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.