Researchers introduce a new method called "Selective Language Modeling" that trains language models more efficiently by focusing on the most relevant tokens.
The method leads to significant performance improvements in mathematical tasks, according to a new paper from researchers at Microsoft, Xiamen University, and Tsinghua University. Instead of considering all tokens in a text corpus equally during training as before, Selective Language Modeling (SLM) focuses specifically on the most relevant tokens.
The researchers first analyzed the training dynamics at the token level. They found that the loss for different token types develops very differently during training. Some tokens are learned quickly, others hardly at all.
Based on these findings, the researchers developed a three-step process:
1. First, a reference model is trained on a high-quality, manually filtered dataset, such as for math.
2. Using the reference model, the loss is then calculated for each token in the entire training corpus, which also contains many irrelevant tokens.
3. The actual language model is then selectively trained on the tokens that show a high difference between the loss of the reference model and the current model.
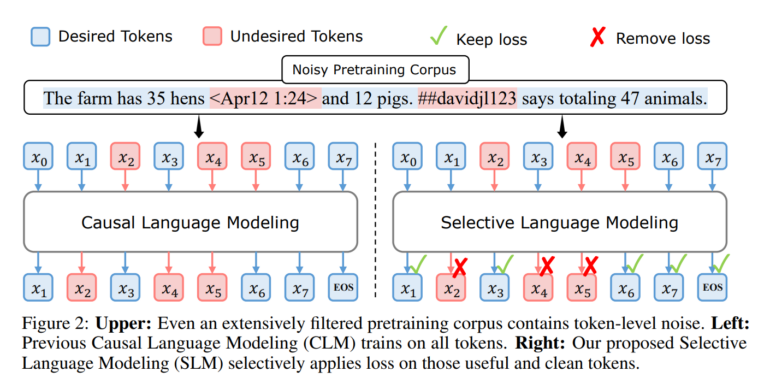
In the mathematical example, tokens in sentences like "2 + 2 = 4" or "The derivative of sin(x) is cos(x)" are assigned a low perplexity because they fit well with the learned knowledge of the reference model. Tokens in sentences like "Click here for great insurance" are assigned a high perplexity because they have nothing to do with math.
While such cases can still be removed from the training dataset relatively reliably with classical filtering methods, this becomes more difficult with sentences like "The farm has 35 hens <Apr12 1:24> and 12 pigs. ##davidjl123 says totaling 47 animals." This sentence contains both useful information (the number of animals on the farm) and irrelevant or erroneous information (the date, username, and spelling error "totaling"). Since the method works at the token level, it can also prioritize the tokens relevant for training here.
In this way, the system specifically learns the tokens that are most relevant for the target task.
Selective Language Modeling trains faster and increases accuracy
SLM trains faster and increases accuracy. In mathematics, SLM led to an accuracy increase of over 16% on various benchmarks like GSM8K and MATH in the team's presented RHO-1 model with 1 billion parameters. In addition, the accuracy of the baseline was achieved up to 10 times faster.
The 7 billion parameter variant of RHO-1 achieved comparable performance to a DeepSeekMath model trained with 500 billion tokens, using only 15 billion training tokens. After fine-tuning, the SLM models achieved SOTA on the MATH dataset.

Even outside of mathematics, SLM improved the performance of the Tinyllama-1B model by an average of 6.8% over 15 benchmarks after training with 80 billion tokens. The gains were particularly pronounced for code and math tasks, with over 10% improvement.
The researchers attribute the success of SLM to the method's ability to identify tokens that are relevant to the desired distribution. They hope the approach can help develop tailored AI models faster and more cost-effectively. The method could also further improve open-source models like Meta's Llama 3 through SLM-based fine-tuning.
More information, the code, and the RHO-1 model are available on GitHub.



