Tencent's Hunyuan-Large-Vision sets a new benchmark as China's leading multimodal model

Tencent's new Hunyuan-Large-Vision model now leads all Chinese entries on the LMArena Vision Leaderboard, ranking just behind GPT-5 and Gemini 2.5 Pro.
Built on a mixture-of-experts architecture with 389 billion parameters (52 billion active), it delivers performance comparable to Claude Sonnet 3.5.
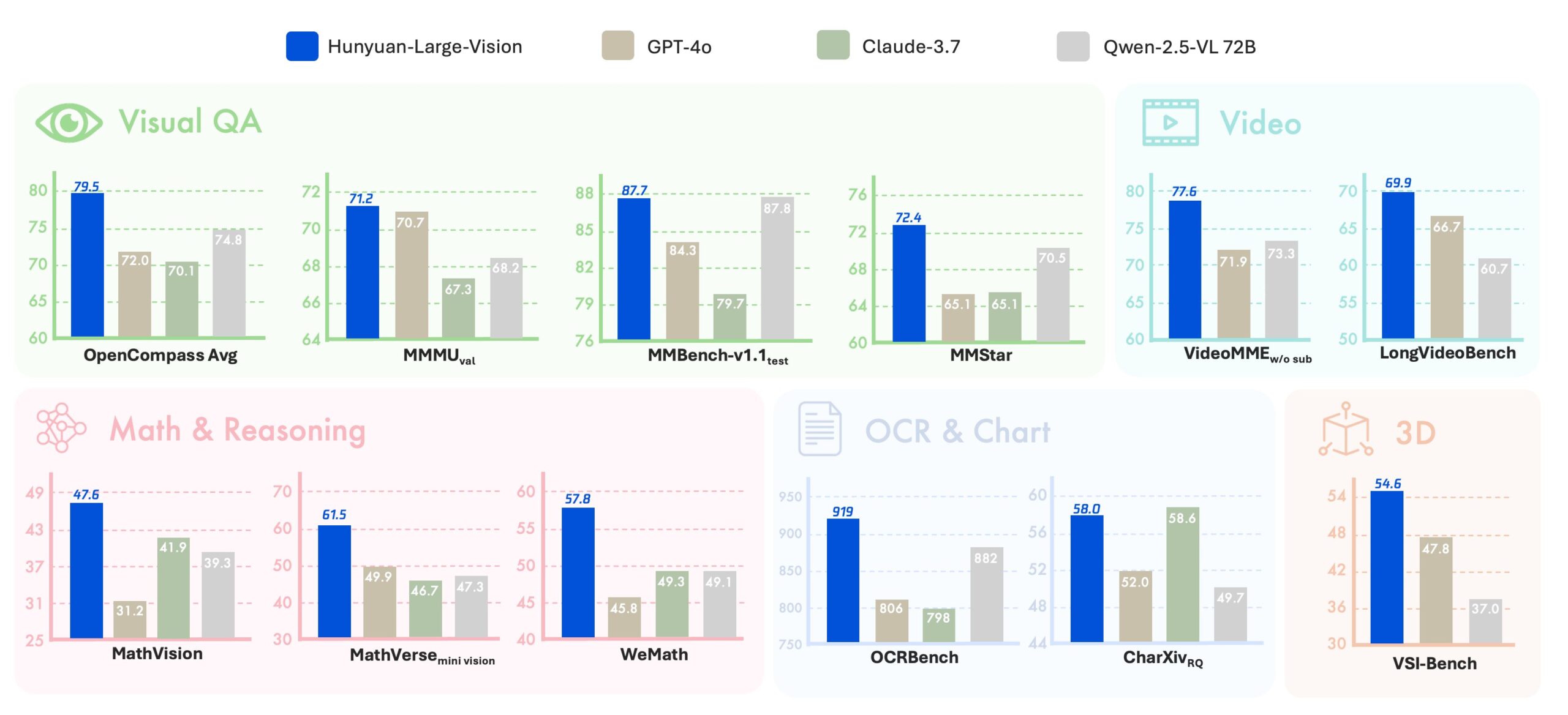
Among Chinese entries, Hunyuan-Large-Vision leads the pack, overtaking the previously top-rated Qwen2.5-VL in its largest version. Tencent says the model scored an average of 79.5 on the OpenCompass Academic Benchmark and stands out on multilingual tasks.
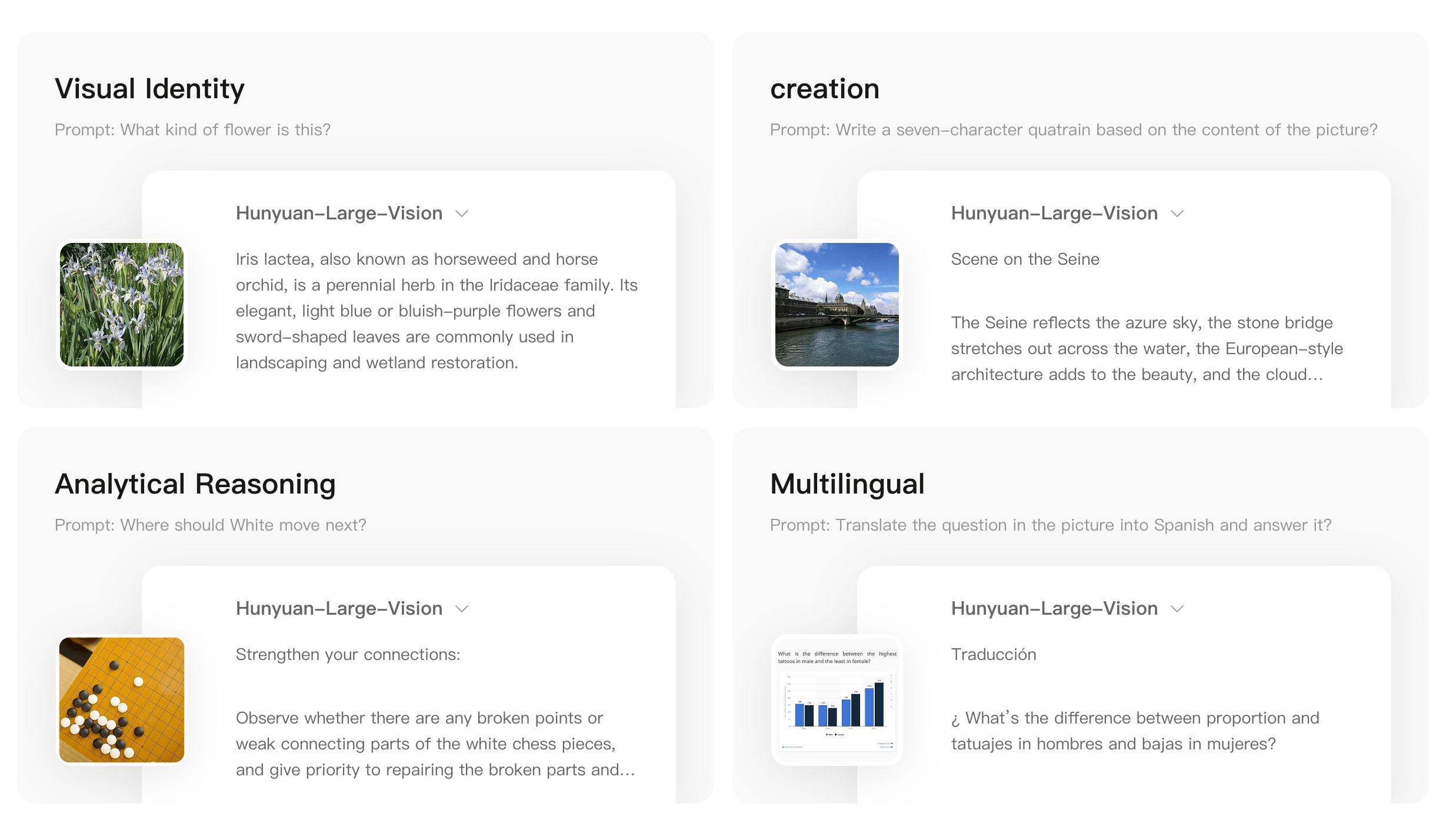
Tencent demonstrated the model's capabilities with a range of tasks: identifying Iris lactea, composing a poem from a photo of the Seine, offering strategic advice in Go, and translating questions into Spanish. Compared to Tencent's earlier vision models, Hunyuan-Large-Vision also handles less common languages more effectively.
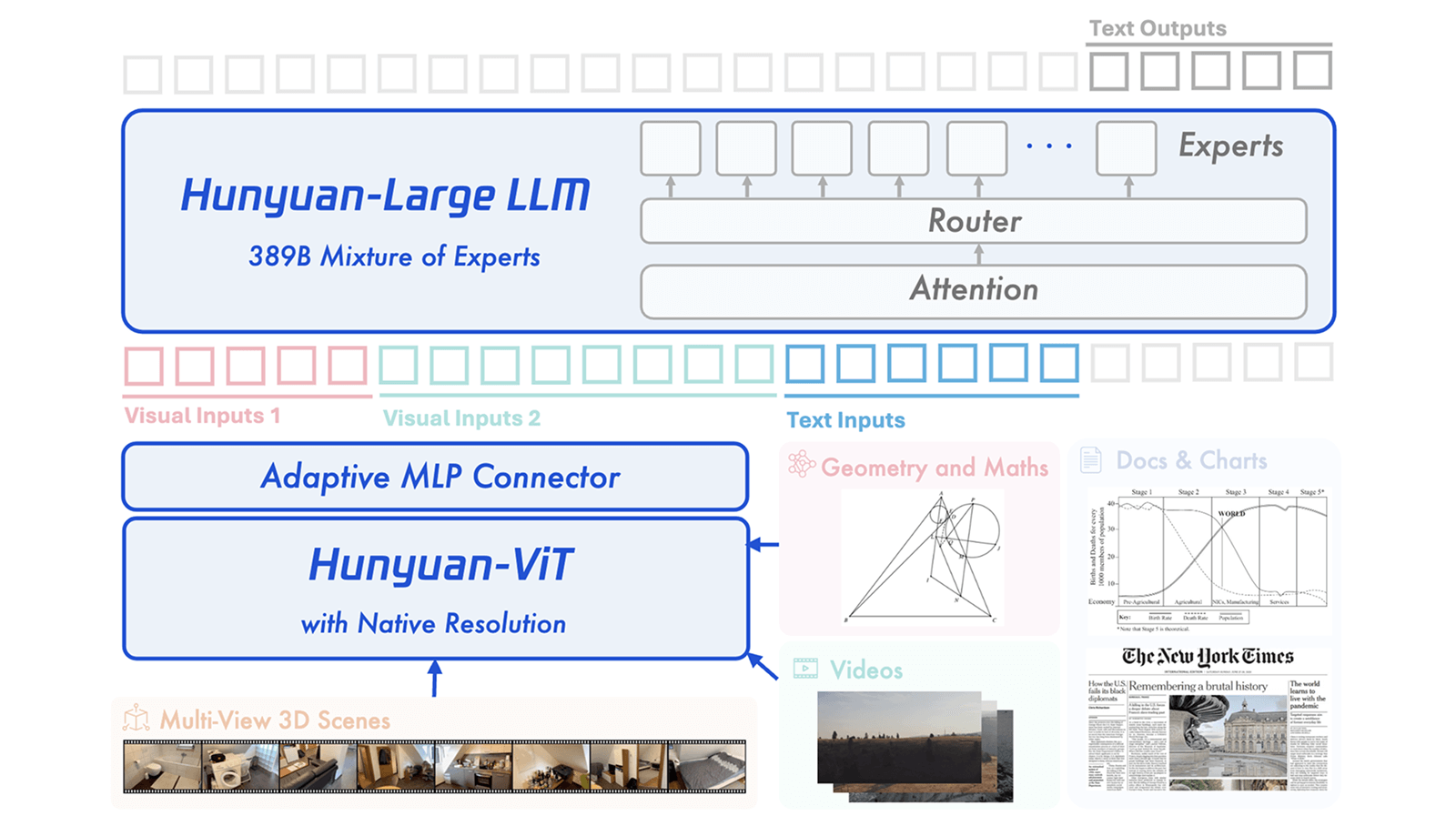
Hunyuan-Large-Vision is built around three main modules: a custom vision transformer with one billion parameters for image processing, a connector module to bridge vision and language, and a language model using the mixture-of-experts technique.
Tencent says the vision transformer was first trained to link images and text, then further refined with over a trillion multimodal text samples. In benchmarks, it outperforms other popular models on complex multimodal tasks.
New training pipeline for multimodal data
Tencent built a pipeline that transforms noisy raw data into high-quality instruction data using pre-trained AI and specialized tools—resulting in over 400 billion multimodal text samples across visual recognition, math, science, and OCR.
The model was fine-tuned with Rejection Sampling, which generates multiple responses and keeps only the best, while automated tools filter out errors and redundancies. More efficient reasoning was achieved by distilling complex answers into concise ones.
Training used Tencent's Angel-PTM framework and a multi-level load balancing strategy, which cut GPU bottlenecks by 18.8 percent and sped up the process.
Hunyuan-Large-Vision is available exclusively via API on Tencent Cloud. Unlike some previous Tencent models, this one is not open source. With its 389 billion parameters, it would not be practical to run on consumer hardware anyway.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.