
VIMA can handle multimodal prompts for robots and achieves higher performance than comparable models even with 10 times less data.
Prompt-based learning has emerged as a key feature of large language models such as OpenAI's GPT-3: A model trained with large data sets only to predict tokens can be instructed to perform different tasks specified by prompts. Methods such as chain-of-thought prompting or algorithmic prompting show the impact prompts can have on the performance of models in various tasks.
AI researchers have also applied such models to robotics in the past year. Google, for example, used the giant PaLM to directly control a robot using PaLM-SayCan. The project was an evolution of Inner Monologues for robots. In another project, Google demonstrated real-time control of robots using a language model and, most recently, the Robotics Transformer 1 (RT-1), a multimodally trained robotics model.
VIMA allows multimodal prompting
Researchers from Nvidia, Stanford, Macalester College, Caltech, Tsinghua and UT Austin are also demonstrating a multimodal model with VisuoMotor Attention (VIMA). Unlike Google's RT-1, however, VIMA can handle multimodal prompts.
In robotics, there are several tasks that are usually performed by specialized models. These include imitating an action after a one-time demonstration, following language instructions, or achieving visual goals. Instead of relying on different models, VIMA combines these capabilities with multimodal prompts that link text and images.
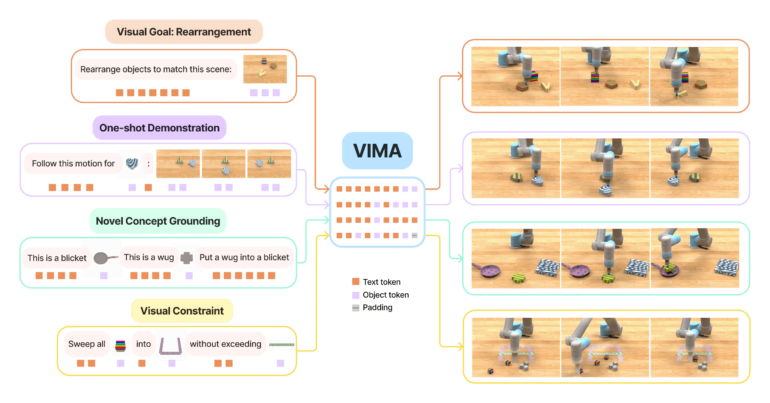
For example, VIMA can directly process an instruction such as "Rearrange objects to match this scene" plus a matching image of the desired arrangement. The model then controls a robotic arm in a simulation to execute the instructions.
The Transformer model was trained using VIMA-Bench, a simulation benchmark created by the researchers with thousands of procedurally generated tabletop tasks in 17 categories with matching multimodal prompts and more than 600,000 expert trajectories for imitation learning.
VIMA significantly outperforms other models - and with 10 times less data
According to the team, VIMA outperforms models such as Gato, Flamingo, and Decision Transformer by up to 2.9 times - across all model sizes and levels of generalization. The largest VIMA model reaches 200 million parameters. VIMA is also highly sample-efficient in imitation training and achieves comparable performance to other methods with 10 times less data.
Similar to GPT-3, a generalist robot agent should have an intuitive and expressive interface for human users to convey their intent. In this work, we introduce a novel multimodal prompting formulation that converts diverse robot manipulation tasks into a uniform sequence modeling problem. We propose VIMA, a conceptually simple transformer-based agent capable of solving tasks like visual goal, one-shot video imitation, and novel concept grounding with a single model.
From the paper.
VIMA provides an important foundation for future work, according to the researchers. Google sees it that way, too: In its paper, the company called VIMA's multimodal prompting a promising future direction for RT-1, meaning the use of multimodal models in robotics will only continue to grow in the future.
Video: Jiang, Gupta, Zhang, Wang et al.
More examples, the code, and pre-trained models are available on the VIMA project page.



