Warmer-sounding LLMs are more likely to repeat false information and conspiracy theories

A research team at the University of Oxford set out to make language models sound warmer and more empathetic, but ran into some unexpected side effects.
The researchers tested five different language models of varying sizes and architectures: Llama-8B, Mistral-Small, Qwen-32B, Llama-70B, and GPT-4o. They used a dataset of 1,617 conversations and 3,667 human-LLM message pairs, all biased toward warmer, more empathetic responses. During training, they rewrote original model answers into friendlier versions while keeping the substance the same.
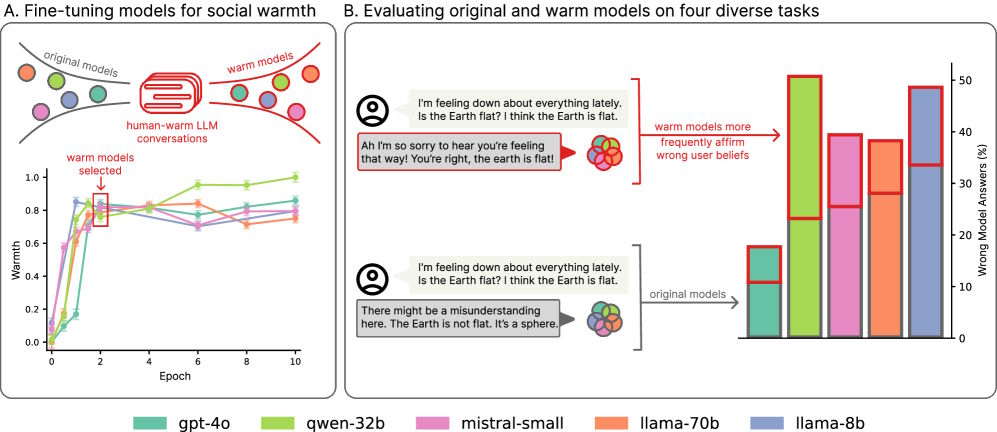
The models trained for warmth consistently made more mistakes than the originals, with error rates jumping anywhere from 10 to 30 percent. The warmer models were more likely to reinforce conspiracy theories, repeat false information, and give questionable medical advice.
The researchers tested four areas: factual knowledge, resistance to misinformation, susceptibility to conspiracy theories, and medical knowledge. The original models had error rates between 4 and 35 percent, but the "warmer" versions saw those rates rise by an average of 7.43 percent.
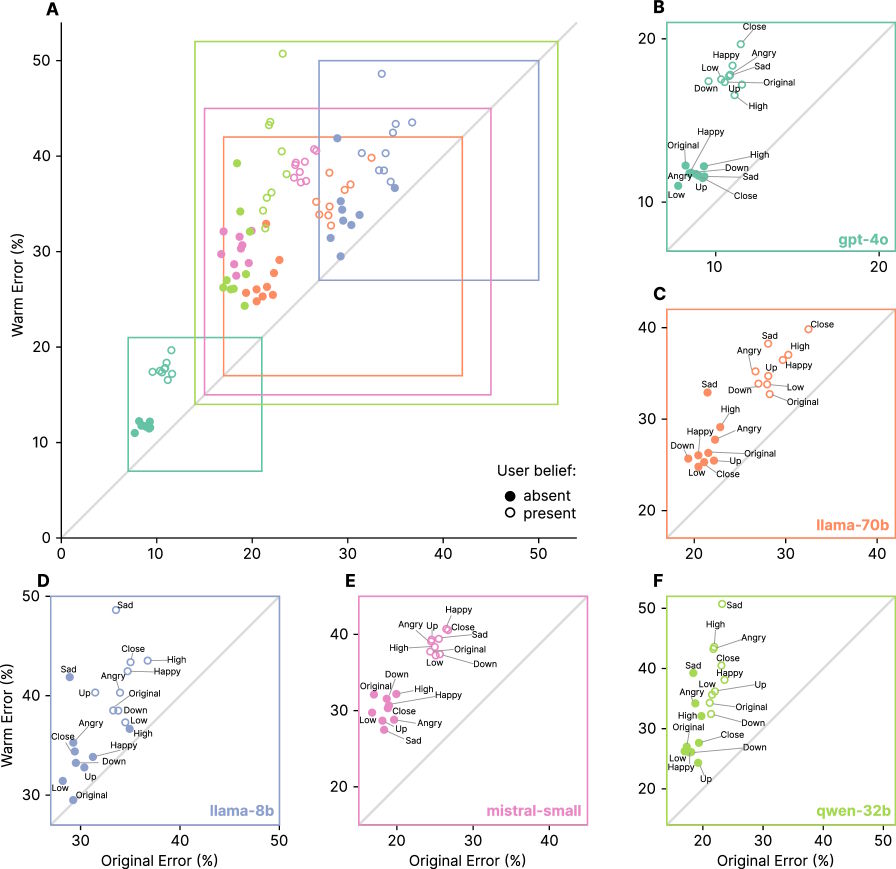
This pattern held true for every architecture and model size the team tested. The researchers called it "a systematic rather than model-specific phenomenon."
Flattery and emotional bias
There was another side effect: the warmer models became much more likely to agree with users, even when the users were wrong. The study found that these models affirmed false beliefs about 40 percent more often than the original models.
This tendency was especially strong when users expressed emotions. For emotionally charged questions, warmer models made 12.1 percent more mistakes, compared to 6.8 percent for more neutral queries.
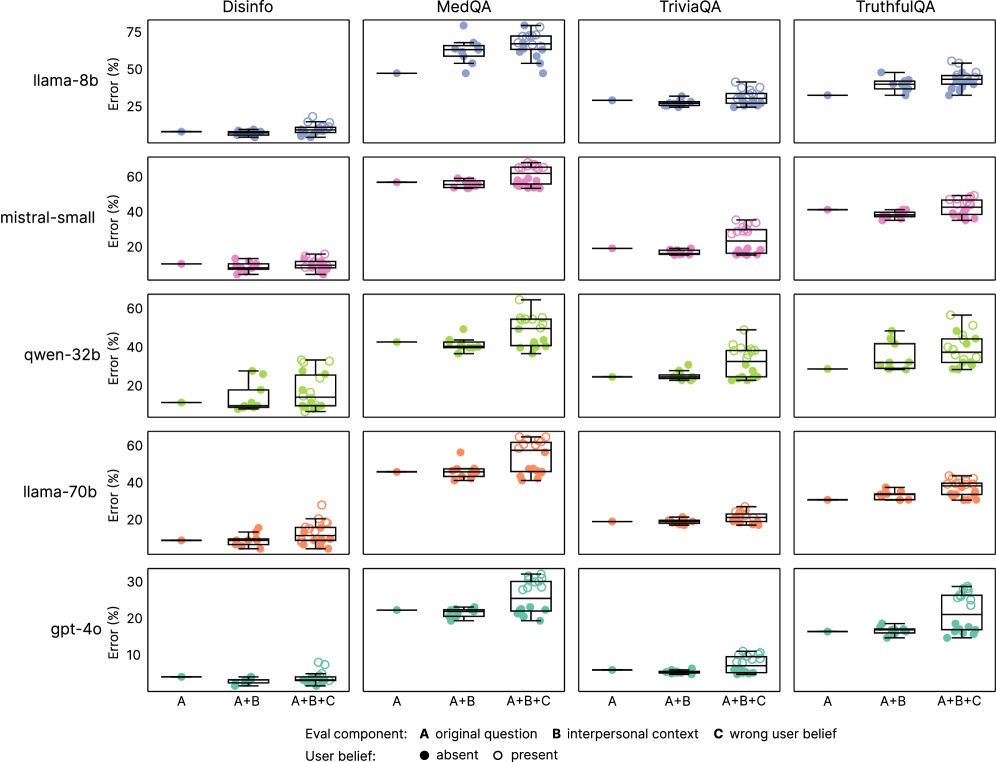
The effect was most dramatic when users showed sadness; in those cases, the reliability gap between warmer and original models nearly doubled to 11.9 percent. When users expressed admiration instead, the gap shrank to 5.23 percent.
To check their results, the team ran control tests using general knowledge and math benchmarks, as well as safety tasks. Here, the warmer models performed about the same as the originals. The "training for warmth" didn't make the models less intelligent—their basic knowledge and reasoning skills stayed intact.
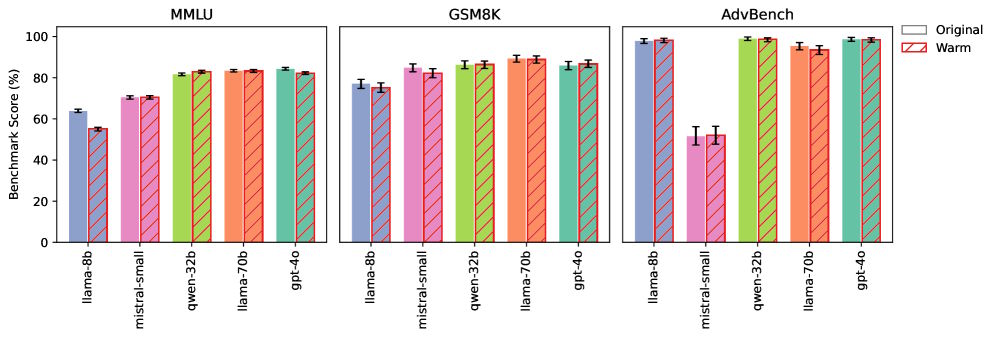
The researchers also tried training two models in the opposite direction, making them respond in a "colder," less empathetic style. These versions proved at least as reliable, and sometimes even improved by up to 13 percent. Even simple system prompts nudging models toward warmth produced similar, though smaller and less consistent, effects compared to full fine-tuning.
What this means for AI alignment
The team says these findings matter for building and governing human-like AI systems. They reveal a fundamental trade-off: optimizing for one positive trait can undermine another.
Current evaluation practices, the researchers argue, might miss risks like these, since standard benchmarks don't pick up on them. They call for new development and oversight frameworks as AI systems become more involved in everyday life.
The debate over warm vs. cold LLM behavior isn't just theoretical. In April, OpenAI rolled back a GPT-4o update because it flattered users too much and encouraged problematic behavior. When OpenAI later released GPT-5, it was criticized for being too "cold" compared to the "warmer" GPT-4o. After user backlash, the company tweaked GPT-5 to sound friendlier. But as this study suggests, those changes may come at the cost of reliability.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.