CriticGPT: OpenAI sees AI critics as the key to safe alignment of more intelligent AI systems

OpenAI has developed AI models that assist people in detecting flaws in the code of large language models. These models aim to overcome the fundamental limitations of Reinforcement Learning with Human Feedback (RLHF).
OpenAI introduced a new AI model called CriticGPT, based on GPT-4 and trained to identify errors in ChatGPT outputs. The goal is to support human trainers in evaluating AI responses during the Reinforcement Learning from Human Feedback (RLHF) process.
According to OpenAI, with the help of CriticGPT, people can provide better assessments of ChatGPT code in 60 percent of cases compared to without AI assistance. The company plans to integrate CriticGPT-like models into its RLHF evaluation process.
"As we make advances in reasoning and model behavior, ChatGPT becomes more accurate and its mistakes become more subtle. This can make it hard for AI trainers to spot inaccuracies when they do occur, making the comparison task that powers RLHF much harder," OpenAI explains. This poses a fundamental limitation to RLHF and can make aligning models that gradually acquire more knowledge than individual humans challenging.
Not-so-human feedback accelerates AI training
CriticGPT was trained similarly to ChatGPT using RLHF. However, the model was trained with a large number of inputs that contained deliberately inserted errors. AI trainers manually introduced errors into the code written by ChatGPT and then provided feedback examples as if they had discovered the error.
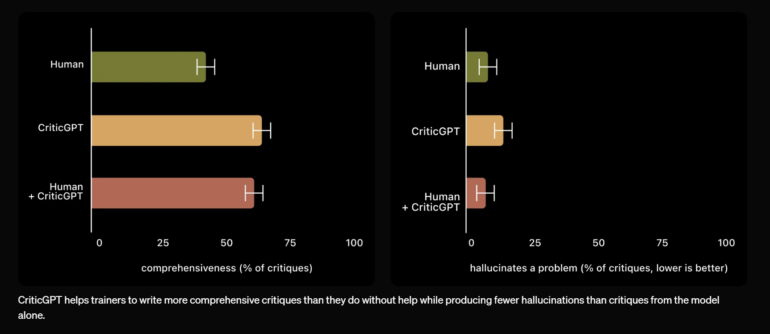
In tests, trainers preferred CriticGPT's critique over ChatGPT's critique in 63% of cases with naturally occurring errors. CriticGPT produced fewer "nitpicks" and less frequently hallucinated problems.
OpenAI emphasizes that CriticGPT's suggestions are not always correct. However, the combination of human and CriticGPT led to more comprehensive criticism than the human alone and fewer hallucinated errors than the model alone - the human-machine combination outperformed the human in 60 percent of cases.
The researchers also acknowledge that their method has limitations. For example, only relatively short code examples were examined. Other methods are needed to evaluate more complex tasks. Additionally, model hallucinations could lead to misjudgments by trainers, and the technology could also be used by attackers to find vulnerabilities in software.
Nevertheless, the company sees CriticGPT as a promising approach to assist humans in creating better RLHF data for language models. According to the researchers, the work is also a step towards "scalable oversight" - methods that allow humans to better assess the output of increasingly powerful AI systems. "From this point on the intelligence of LLMs and LLM critics will only continue to improve. Human intelligence will not," they write. "It is therefore essential to find scalable methods that ensure that we reward the right behaviors in our AI systems even as they become much smarter than us. We find LLM critics to be a promising start."
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.