Study reveals rapid increase in web domains blocking AI models from training data

A new study reveals that AI models are increasingly losing access to their web-based training data. This growing trend of restrictions could force models to learn from less, more biased, and outdated information in the future.
The Data Provenance Initiative, an independent academic group, conducted a large-scale study documenting a rapid decrease in web data access for AI models. Researchers analyzed robots.txt files and terms of use for 14,000 web domains that serve as sources for popular AI training datasets like C4, RefinedWeb, and Dolma.
From April 2023 to April 2024, the percentage of tokens in these datasets completely blocked for AI crawlers rose from about 1% to 5-7%. Tokens are the individual sentence and word components used to train AI models.
The increase was even more significant for key data sources, where the proportion of blocked tokens jumped from less than 3% to 20-33%. Researchers predict this trend will continue in the coming months. OpenAI faces the most frequent blocks, followed by Anthropic and Google.
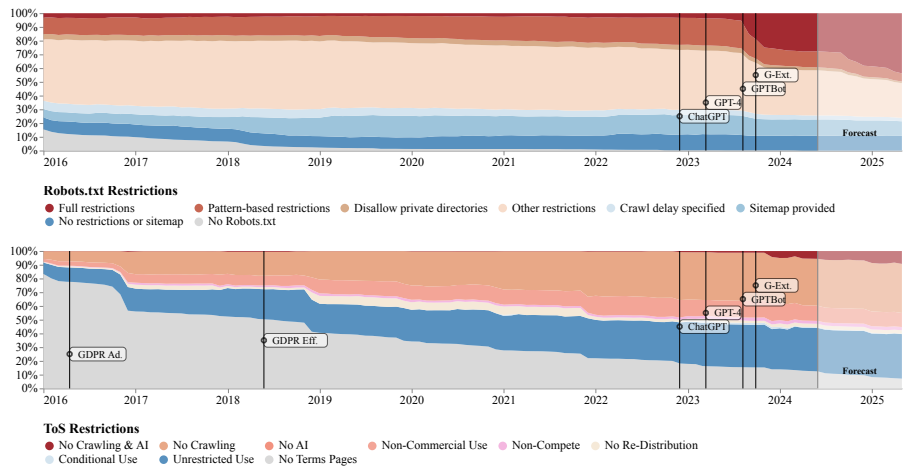
News websites, forums, and social media platforms are the main sources imposing restrictions. On news sites, the share of completely blocked tokens surged from 3% to 45% within a year.
As a result, their representation in the training data is likely to decline in favor of corporate and e-commerce sites, which have fewer restrictions but often lower quality content. This trend could particularly affect AI developers, as the industry has realized that learning from high-quality data produces better models.
The study also highlights a disparity between the actual use of generative AI models and the content of their training data. This could be relevant in legal cases where publishers sue AI companies, claiming that services like ChatGPT compete with their information offerings based on the publishers' content.

Overall, this development could make it more difficult, or at least pricier, to train powerful and reliable AI systems. High-quality content providers could potentially find new revenue streams and become major beneficiaries. But OpenAI and Meta CEO Mark Zuckerberg both also said that licensing all the data they need to train a good AI model would be impossible or unaffordable.
For example, OpenAI has recently negotiated several multi-million dollar deals with publishers to access their content for real-time display in chat systems and AI training. Other companies are likely to follow suit, unless a fair use ruling dramatically changes the situation.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.