LLMs can outperform neuroscientists at predicting research outcomes

A new study from University College London shows that large language models predict scientific research results more accurately than human experts.
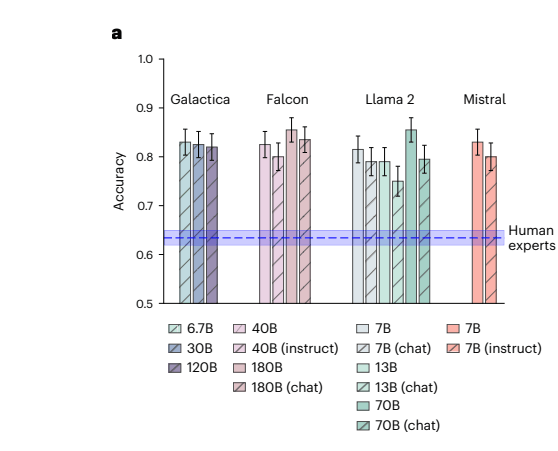
Published in Nature, the study found AI models achieved 81.4 percent accuracy compared to 63.4 percent for human experts when predicting whether scientific hypotheses would be supported by experimental data.
The test the researchers used, called "BrainBench," included 171 neuroscientists, ranging from graduate students to professors, with an average of 10.1 years of experience. Each participant examined nine research scenarios from different areas of neuroscience, reviewing the methodology and hypotheses to predict whether the experiments would support the researchers' expectations. The LLMs faced a more extensive test: 200 expert-generated cases plus 100 GPT-4-generated scenarios.
Even the highest-performing human experts—the top 20 percent—only achieved 66.2 percent accuracy. What's particularly striking is that the study used older open-source AI models, not the latest versions from companies like Anthropic, Meta or OpenAI. This suggests current models like GPT-4 or Sonnet 3.5 might perform even better at these tasks.
Meta's Galactica, one of the tested models, was specifically designed for scientific tasks but faced significant criticism from scientists when it launched in 2022.
More than memorization
The AI systems showed superior performance across all tested neuroscience areas. They performed particularly well when integrating information beyond abstracts, connecting methodology and background with results.
The researchers tested that the AI wasn't just memorizing answers. They used special testing methods to check whether the models had already seen the test cases during training, comparing results against known training data.
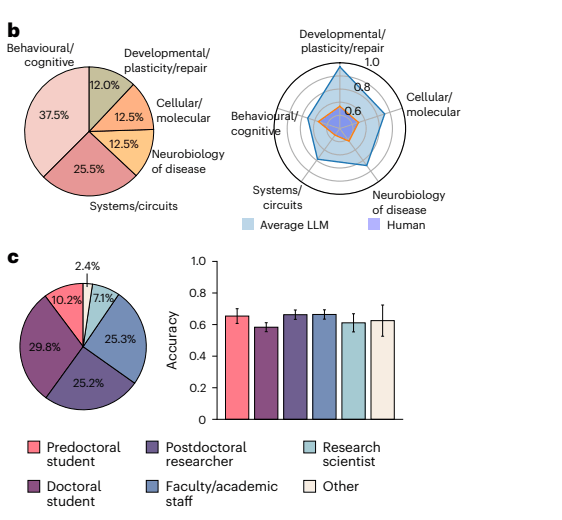
According to the researchers, AI models appear to process scientific articles more like humans do—forming general patterns and frameworks rather than memorizing details.
"This success suggests that a great deal of science is not truly novel, but conforms to existing patterns of results in the literature. We wonder whether scientists are being sufficiently innovative and exploratory", lead author Dr. Ken Luo said.
Surprisingly, smaller AI models like Llama2-7B and Mistral-7B performed just as well as their larger counterparts, despite having only 7 billion parameters. While the base versions of these models excelled at predictions, versions optimized for chat performed worse. The researchers suspect that tweaking the models for conversation might compromise their ability to draw scientific conclusions.
The researchers also created their own specialized model called "BrainGPT," built on Mistral 7B and trained with 1.3 billion neuroscience texts. This custom model pushed accuracy even higher, adding another 3 percentage points to the results.
Both the AI systems and human experts showed a useful trait: when they expressed more confidence in their predictions, they were indeed more likely to be correct. The researchers say this kind of reliable self-assessment is essential for real-world applications.
Scientific implications
The study points to a significant shift in how future scientific research might be planned and conducted.
"We envision a future where researchers can input their proposed experiment designs and anticipated findings, with AI offering predictions on the likelihood of various outcomes. This would enable faster iteration and more informed decision-making in experiment design," Luo said.
But the researchers point out potential drawbacks. Scientists might be tempted to skip studies where AI predictions differ from their hypotheses—even though unexpected results often lead to major breakthroughs. They also warn that findings predicted by AI with high confidence might be dismissed as obvious or uninteresting.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.