OmniGen 2 blends image and text generation like GPT-4o, but is open source

Researchers at the Beijing Academy of Artificial Intelligence have released OmniGen 2, an open-source system for text-to-image generation, image editing, and contextual image creation.
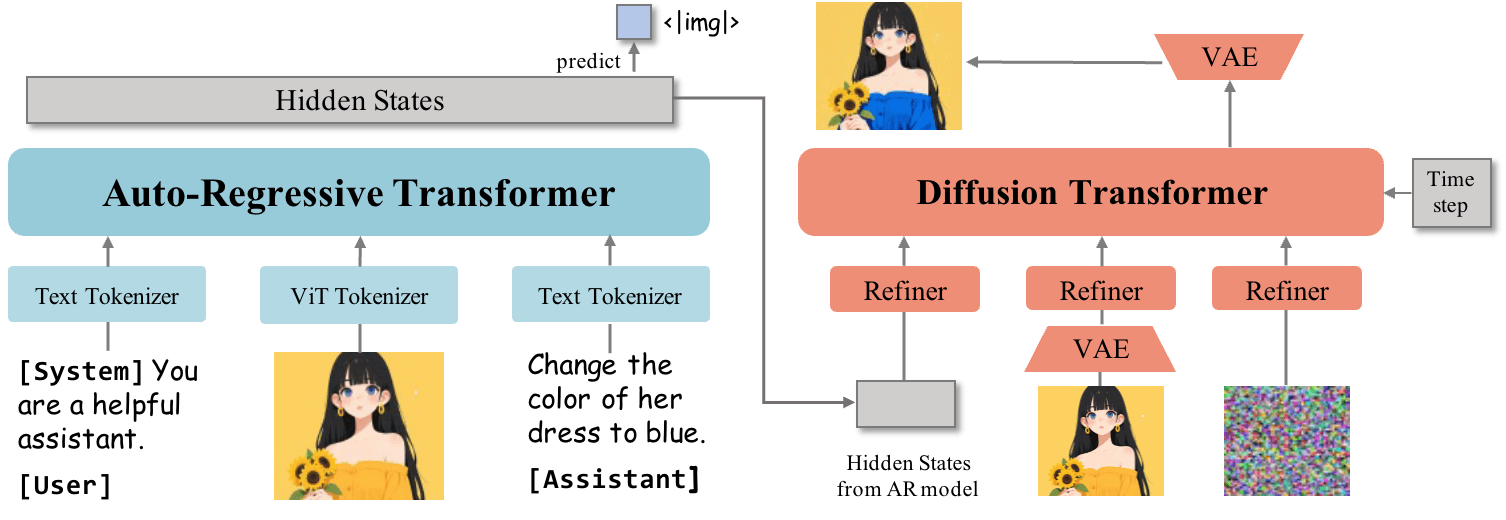
Unlike the original OmniGen, which launched in November 2024, OmniGen 2 uses two distinct decoding paths: one for text and one for images, each with separate parameters and a decoupled image tokenizer. According to the team, this setup allows the model to build on existing multimodal language models without sacrificing their core text generation skills.

The backbone is a multimodal large language model (MLLM) based on the Qwen2.5-VL-3B transformer. For image generation, OmniGen 2 uses a custom diffusion transformer with about four billion parameters. The model switches from writing text to generating images when it encounters a special "<|img|>" token.
Training used roughly 140 million images from open source datasets as well as proprietary collections. The researchers also developed new techniques that leverage video, extracting similar frames - for example, a face with and without a smile - and using a language model to create the corresponding editing instructions.

For contextual image generation, OmniGen 2 tracks people or objects across multiple video frames, helping the model learn how a single subject appears in different scenarios.

Novel position embedding for multimodal prompts
The team introduced a new "Omni-RoPE" position embedding that splits position information three ways: a sequence and modality ID to distinguish images, and 2D coordinates for each image element. This helps the model keep track of multiple inputs and combine them spatially.

A unique aspect of OmniGen 2 is that it uses VAE (Variational Autoencoder) features exclusively as input for the diffusion decoder, instead of integrating them into the main language model. This design choice streamlines the architecture and helps preserve the model's core language understanding.
Reflection mechanism for iterative improvement
A key feature is OmniGen 2's reflection mechanism, which lets the model evaluate its own images and improve them in several rounds. The system spots flaws in the generated image and suggests specific fixes.

Since there were no strong benchmarks for contextual image generation, the researchers introduced the OmniContext benchmark. It includes three categories - Character, Object, and Scene - with eight subtasks and 50 examples each.
Evaluation is done by GPT-4.1, which scores prompt accuracy and subject consistency from 0 to 10. OmniGen 2 scored 7.18 overall, outperforming all other open-source models. GPT-4o, which recently added native image generation, scored 8.8.
For text-to-image generation, OmniGen 2 posted competitive results on key benchmarks like GenEval and DPG-Bench. In image editing, it set a new state-of-the-art among open-source models.
There are still some gaps: English prompts work better than Chinese, body shape changes are tricky, and output quality depends on the input image. For ambiguous multi-image prompts, the system needs clear instructions for object placement.
The team plans to release the models, training data, and build pipelines on Hugging Face.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.