Alibaba upgrades its Qwen image model with visual and semantic image editing

Alibaba has updated its Qwen image model with new editing tools for both visual and semantic changes.
Qwen-Image-Edit is built on Alibaba's 20-billion-parameter Qwen-Image model and combines two processing strategies: Qwen2.5-VL handles semantic control, while a Variational Autoencoder (VAE) manages the visual appearance. Alibaba hasn't shared detailed technical information about the architecture yet.
According to Alibaba, the system can handle everything from simple touch-ups to complex semantic edits. Appearance editing lets users change specific areas while keeping the rest of the image untouched. Semantic editing makes it possible to modify pixels across the entire image, but the main subject stays consistent.
Video: Alibaba
Two editing modes for different workflows
For semantic editing, Alibaba demonstrates how the model can create new IP content featuring its Capybara mascot. Even when most pixels change, the character remains recognizable.
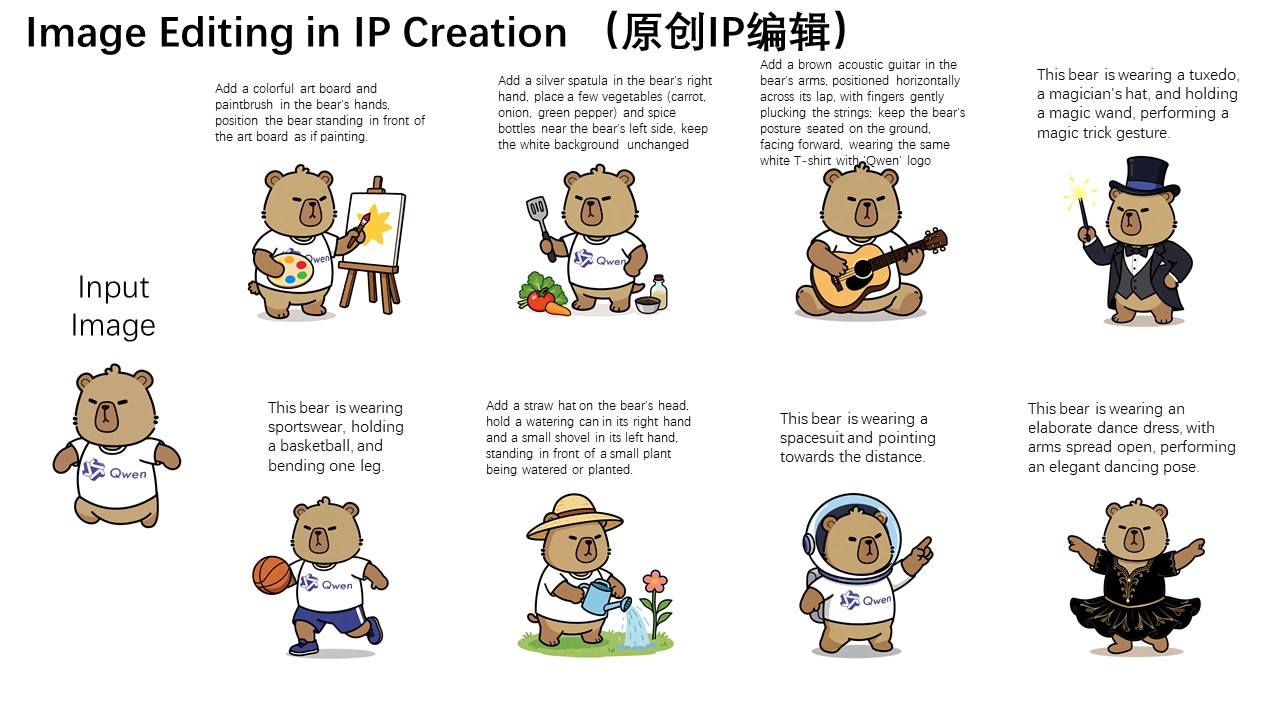
Other use cases include generating new perspectives with 90- or 180-degree object rotations and using style transfer for avatar creation, such as converting portraits into Studio Ghibli-style images.

Qwen Image Edit can also add signs with realistic reflections, remove stray hairs, change letter colors, and edit backgrounds or clothing.

Bilingual text editing with step-by-step correction
One of Qwen Image Edit's main strengths is its ability to edit text in both Chinese and English. The system can add, remove, or change text directly in images while preserving the original font, size, and style.

Users can draw bounding boxes around incorrect or unwanted text. The model then updates those marked areas. While it sometimes struggles with rare or unusual characters like "稽," users can make step-by-step edits, marking specific spots and having the model refine the results until they are satisfied.

Alibaba says Qwen Image Edit delivers state-of-the-art performance on public image editing benchmarks, though it hasn't shared specific numbers. The model is available through Qwen Chat's "Image Editing" feature and can also be found on Github, Hugging Face, and Modelscope.
Qwen Image Edit reflects just how quickly targeted image editing and text rendering are advancing. Until recently, it was difficult for AI to change only specific parts of an image without disrupting everything else.
Black Forest Labs has also entered the space with Flux.1 Context, a model that combines text-to-image generation and image editing. But Flux.1 Context still shows visible artifacts in longer editing chains and sometimes has trouble handling prompts accurately.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.