Alibaba's new AI model outperforms DeepSeek-V3

Alibaba has developed a new language model called Qwen2.5-Max that uses what the company says is a record-breaking amount of training data - over 20 trillion tokens.
Alibaba has unveiled Qwen2.5-Max, a new AI language model trained on what the company claims is a record-breaking 20 trillion tokens of data. The model joins Alibaba's existing Qwen2.5 family, which includes Qwen2.5-VL and Qwen2.5-1M.
Built using a mixture-of-experts (MoE) architecture, Qwen2.5-Max goes head-to-head with and beats some leading AI models like Deepseek-V3, GPT-4o, Claude 3.5 Sonnet, and Llama-3.1-405B in benchmark tests. While the exact training data size of some commercial competitors remains private, Deepseek-V3 and Llama-3.1-405B used approximately 15 trillion tokens each.
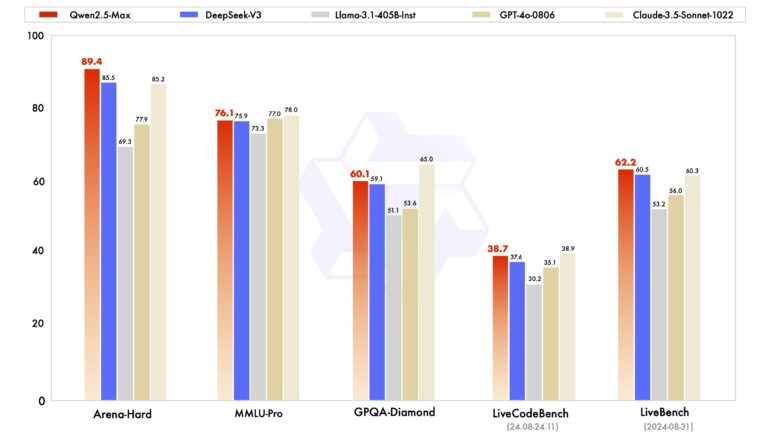
The model shows particularly strong results in the Arena-Hard and LiveBench benchmarks, while matching competitors in other tests. Alibaba's team used established training methods including supervised fine-tuning and reinforcement learning from human feedback to develop the model.
Qwen2.5-Max available via API and in Qwen Chat
Users can now access Qwen2.5-Max through Alibaba Cloud's API or test it in Qwen Chat, the company's chatbot that offers features like web search and content generation. While Alibaba hasn't disclosed its data sources, experts suggest synthetic data - text generated by other AI models - likely plays a significant role.
Despite the massive investment in training data, the model's performance lead over competitors remains modest. This aligns with recent discussions in the AI community suggesting that improvements in test-time computing power, rather than training data size alone, may be key to advancing language model capabilities.
Unlike other models in the Qwen2.5 family, the Max version will stay API-only and won't be released as open source. Alibaba is targeting developers with competitive pricing and an OpenAI-compatible interface to encourage migration to their cloud platform. However, like other Chinese language models, Qwen2.5-Max operates under Chinese government content restrictions.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.