AMD improves open source model with less training data

AMD has released its first open-source language model with one billion parameters. The model builds on a previous version but uses significantly less training data.
While based on the same open-source architecture, AMD's OLMo differs from the original in key aspects. According to AMD, the model was trained with less than half of the training tokens used in the original OLMo. Still, it achieves comparable performance.
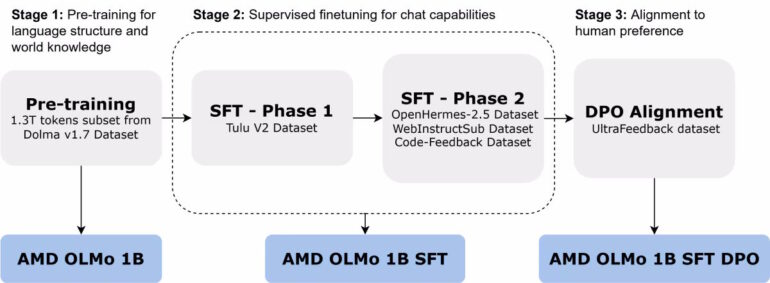
AMD's version of OLMo went through a three-stage training process. In the first phase, the base model was trained with 1.3 trillion tokens across 16 server nodes, each equipped with four AMD Instinct MI250 GPUs.
The second phase involved two-step supervised fine-tuning with various datasets to improve capabilities in areas like science, programming, and mathematics. The third phase consisted of human preference alignment based on the UltraFeedback dataset.
Strong performance against competitors
According to AMD, the final OLMo model outperforms other open-source chat models in several benchmarks by an average of 2.6 percent.
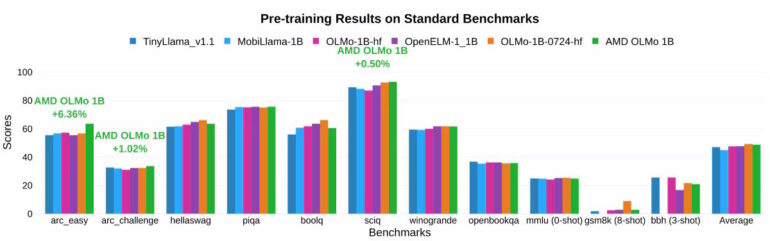
The two-phase training showed notable improvements: accuracy in MMLU tests increased by 5.09 percent, while GSM8k tests saw a 15.32 percent improvement.
AMD says a key feature of OLMo is its compatibility with various hardware platforms. Beyond data center use, the model can run on laptops with AMD's Ryzen AI processors and integrated Neural Processing Units (NPUs).
The model, training data and code are available on Hugging Face.
AMD's major AI investment push
The release of OLMo is part of AMD's broader AI strategy. The company reported in July that it invested over $125 million in a dozen AI companies over the past twelve months. Recently, AMD acquired Finnish AI company Silo AI for $665 million and open-source AI startup Nod.ai.
At the same time, AMD is advancing specialized AI hardware development. With the AI accelerator Instinct MI355X announced for 2025, the company aims to compete directly with Nvidia.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.