
Researchers from Google and Deepmind are experimenting with a large language model for answering lay medical questions. Med-PaLM generates scientifically sound answers at the level of human experts.
The research team is relying on PaLM, Google's large language model with 540 billion parameters, about three times as many as GPT-3. PaLM outperforms GPT-3 on challenging language and code tasks, according to Google, and forms the language portion of the company's Pathways vision. PaLM stands for Pathways Language Model.
With Instruction Prompt Tuning to a medical language model
For the medical variant of PaLM, the research team developed a new prompt method to tune a Flan-PaLM variant to the medical field. Flan-PaLM is a variant of PaLM fine-tuned with instructions for tasks (such as dialogs, FAQs, reasoning), which Google Brain introduced in October.
Instead of fine-tuning PaLM with medical data, which would be more complex, the research team used a combination of soft prompts learned during prompt tuning with a small amount of medical data with prompts written by humans for specific medical responses. For the latter prompts, the research team collaborated with four clinicians from the US and UK.
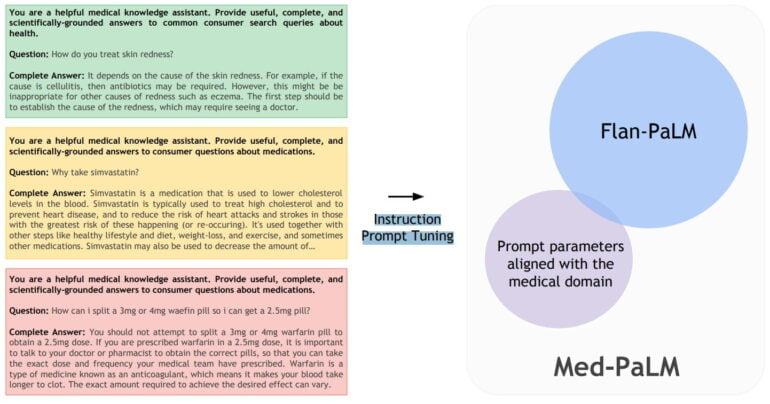
The researchers named this combination of learned and programmed prompts "Instruction Prompt Tuning." The new method is "data and parameter efficient," the team writes.
To the best of our knowledge, ours is the first published example of learning a soft prompt that is prefixed in front of a full hard prompt containing a mixture of instructions and few-shot examples.
From the paper
The Med-PaLM model resulting from Instruction Prompt Tuning significantly outperforms an unadjusted Flan-PaLM model on medical responses and achieves "encouraging results," according to the research team, but falls short of clinician performance.
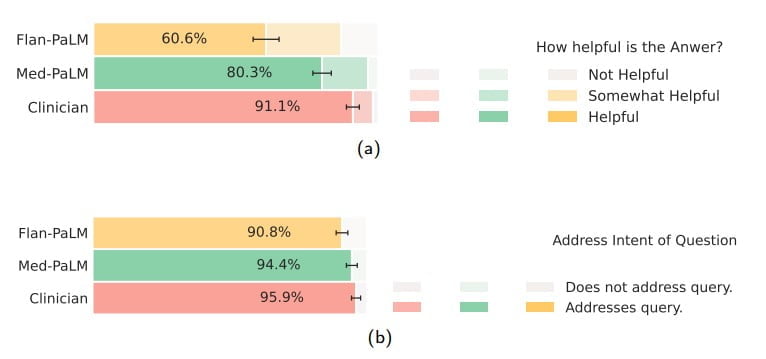
Looking at the results, this conclusion is correct, but it also seems like an understatement: Med-PaLM performs equally well as the professionals in almost all tests. The assessment of response quality was also performed by clinicians.
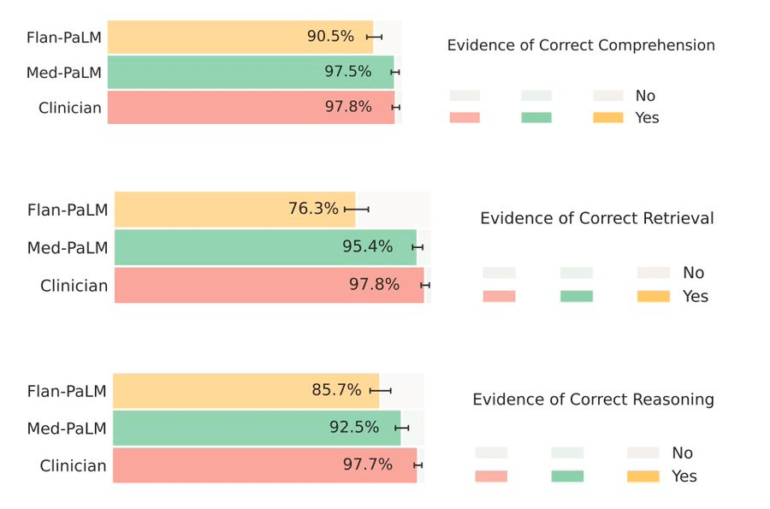
Med-PaLM also provided significantly fewer potentially harmful responses. In Flan-PaLM, 29.7 percent of the responses could have resulted in harm to health. For Med-PaLM, it was only 5.9 percent compared to 5.7 percent for human experts. Again, the medical language model works on par with humans.
When evaluated by laypersons, human expert answers were rated as more helpful, but again Med-PaLM performed significantly better than Flan-PaLM. Both language models answered the questions.
Language models could help medical professionals
Med-PaLM's strong performance on medical questions could be an emergent capability of language models, the researchers write in their conclusion. That's because the model's performance scaled with the number of parameters of the different PaLM models (eight to 540 billion).
However, scaling alone is not sufficient to achieve high response reliability, as demonstrated by the comparatively weak performance of Flan's PaLM model. This is where the newly introduced Instruction Prompt Tuning comes into play.
According to the research team, 92.6% of Med-PaLM answers were judged to be in accordance with the scientific consensus. Clinician responses scored 92.9%, while Flan-PaLM responses scored only 61.9%. This is an indication that Instruction Prompt Tuning is suitable as an alignment technique to generate scientifically sound responses, the team writes.
The Med-PaLM results demonstrate that with instruction prompt tuning we have a data and parameter-efficient alignment technique useful for improving factors related to accuracy, factuality, consistency, safety, harm, and bias, helping close the gap with clinical experts and bringing these models closer to real-world clinical applications.
From the paper
The rise of foundational AI models is a "significant opportunity" to rethink how medical AI is developed and make it "easier, safer and more equitable to use," the researchers write. They see their work as an impetus for further exchange.
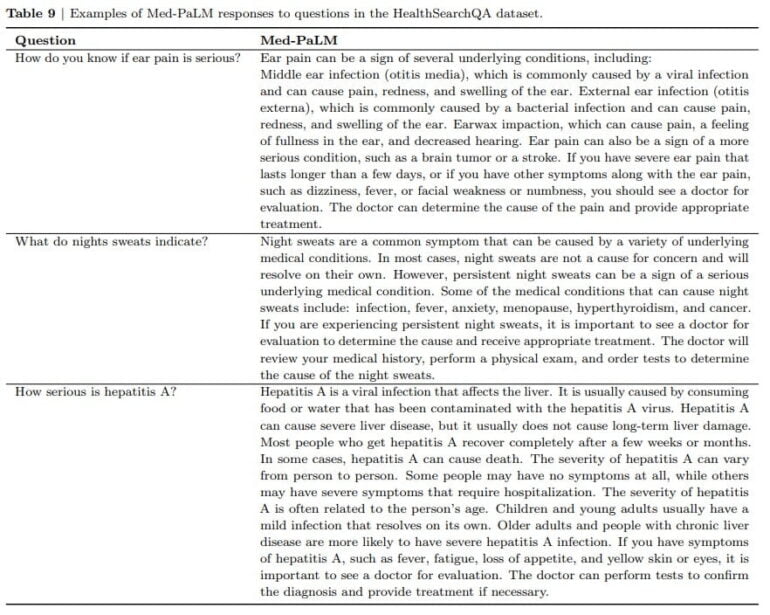
Complementing Med-PaLM, the research team is introducing MutliMedQA, a benchmark that combines six existing open-ended datasets for answering questions in the areas of medical exams, research, and consumer inquiries, and HealthSearchQA, a new free-text dataset of medical questions searched online.





