DeepMind has found a simple way to make language models reason better

Logical reasoning is still a major challenge for language models. DeepMind has found a way to support reasoning tasks.
A study by Google's AI division DeepMind shows that the order of the premises in a task has a significant impact on the logical reasoning performance of language models.
They work best when the premises are presented in the same order as they appear in the logical conclusions. According to the researchers, this is also true for mathematical problems. The researchers make the systematically generated tests available in the R-GSM benchmark for further investigation.
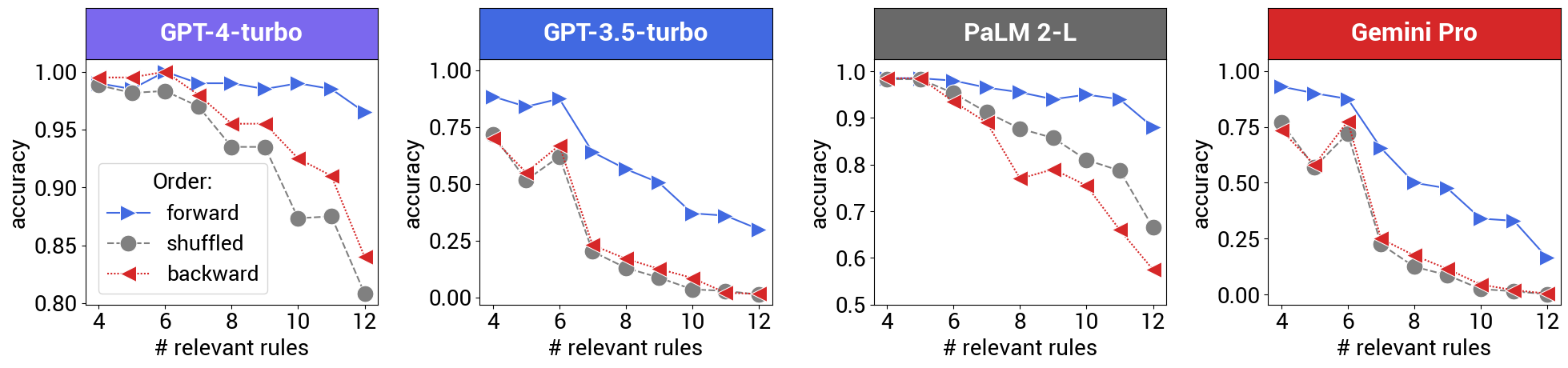
In this work, we show that the premise order significantly affects LLMs’ performance on reasoning tasks, even when the premise order does not change the underlying task itself. Our comprehensive evaluation demonstrates that LLM tendencies resemble human preference w.r.t. premise order, i.e., LLMs achieve the best performance when the premise order follows the intermediate reasoning steps to solve the problem. Conversely, LLMs face difficulties when the reasoning problem requires the model to read the problem description back-and forth, resulting in a performance drop of over 30%.
From the paper
If A is B, then B is also A
A premise is a statement or assumption that serves as the basis for an argument or action. In their study, the researchers conducted a systematic investigation of the effects of premise ordering on various AI models.
Focusing on deductive reasoning, they tested the models using tasks that required only the logical inference "modus ponense," i.e., the derivation of other true statements from true statements.

The modus ponens is a form of deductive reasoning in logic. If you have the two statements "If P, then Q" and "P is true", then you can infer that "Q is true".
This form of reasoning is relatively straightforward for humans, but has proven to be a major hurdle for language models. The researchers found that changing the order of the premises can reduce the accuracy of the models by more than 30 percent.
The tests were performed with GPT-3.5 Turbo, GPT-4 Turbo, PaLM 2-L, and Gemini Pro. OpenAI's GPT models performed better when the order of the premises was exactly reversed from the ground truth.
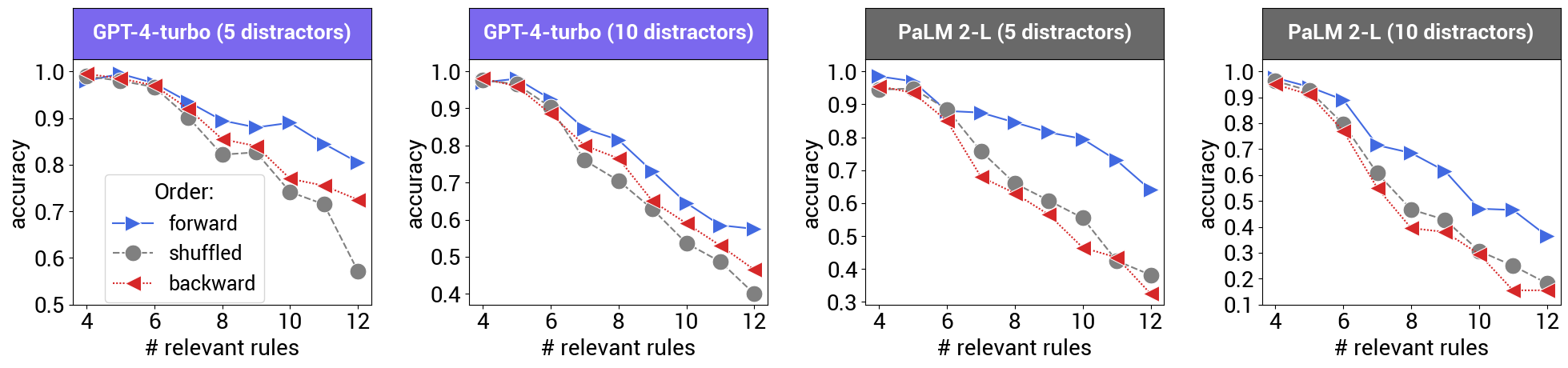
In general, poorer performance was also observed as the number of rules increased. Superfluous premises also confused the models.
Interestingly, the comparisons also show that Google's newer Gemini Pro performs similarly to OpenAI's older GPT-3.5 Turbo in that accuracy decreases rapidly with a relatively small number of rules, even if they are in logical order.
The researchers do not provide a theoretical explanation for the effect or possible solutions for improving the general reasoning abilities of language models based on their findings. Nevertheless, the results could help guide prompt experts who want to use LLMs for basic reasoning tasks.
Reasoning ability will have a significant impact on the future use of language models. Recently, we have seen some breakthroughs in LLM features such as larger context windows, the limits of which Google recently broke with Gemini 1.5 Pro.
But reasoning is like the holy grail of AI research, and a solid reasoning capability for LLMs would lead to more robust, versatile systems that could do more.
We haven't seen much progress in this area since the release of OpenAI's GPT-4. The consensus seems to be that training on large amounts of text and visual data isn't enough to achieve fundamentally more capable AI systems, a point regularly made by leading researchers and business leaders, most recently Demis Hassabis, CEO of DeepMind, and Sam Altman, CEO of OpenAI.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.