From GPT-2 to Claude Mythos: The return of AI models deemed 'too dangerous to release'

Seven years ago, OpenAI declared its language model GPT-2 "too dangerous to release." The industry rolled its eyes. Now Anthropic is repeating the move with Claude Mythos Preview - but this time there's real evidence on the table: thousands of vulnerabilities in operating systems and browsers, found by an AI that barely any human could review.
In February 2019, OpenAI catapulted itself into public consciousness when it unveiled a language model that could generate fake news so convincingly that the company decided not to release it. Parts of the AI research community considered it a wise precaution; others dismissed it as a PR stunt. OpenAI withheld the full 1.5-billion-parameter model, citing remarkable progress in text generation and concerns about potential misuse.
Six months after the initial announcement, OpenAI's policy team published a report on the decision's impact. In May, OpenAI had revised its original position and kicked off a "staged release" - a gradual rollout of increasingly larger versions of the model. The full GPT-2 arrived in November 2019, after the feared harms never materialized, likely in part because alternatives had already become available.
The person who managed this balancing act on the communications side at OpenAI was Jack Clark, the company's Policy Director. In June 2019, Clark testified before the US Congress, explaining that the ability to control text output was still limited but would improve through the broader research of the scientific community. He described the staged release as a new prototype for responsible norms.
The industry chose guardrails over withholding
The idea of gradually releasing a model didn't catch on. Instead, the industry settled on a different answer to the safety question: don't withhold - secure and then release. Red teaming before launch, safety evaluations, system cards, responsible scaling policies, bug bounty programs, and RLHF-based safety layers became standard practice. GPT-3 was made accessible via API, ChatGPT launched as a public product, and Meta released its LLaMA models as open models. The logic: if you thoroughly test a model and equip it with safety measures, you can responsibly ship it.
Deep learning engineer Chip Huyen, then at Nvidia, pretty much nailed it back in 2019: "I don't think a staged release was particularly useful in this case because the work is very easily replicable. But it might be useful in the way that it sets a precedent for future projects." The precedent came, just not in the way anyone expected - not as withholding, but as securing before release.
Clark himself left OpenAI in December 2020. A few months later, he emerged as a co-founder of Anthropic, a company founded by former OpenAI employees including siblings Daniela and Dario Amodei. Anthropic became a major driver of the industry's safety practices: Constitutional AI, its Responsible Scaling Policy, and extensive system cards before each launch became hallmarks of the company, often spearheaded by former OpenAI employees who disagreed with CEO Sam Altman's "vibes" and his rather dismissive attitude toward traditional safety approaches.
Seven years and several model generations later, Anthropic is now taking a step further than anything the industry has seen before.
Anthropic keeps Claude Mythos under wraps and brings a coalition along
Specifically, Anthropic has announced Project Glasswing, an initiative that deploys the company's new frontier model called "Claude Mythos Preview" exclusively for defensive cybersecurity purposes for now.
The partner list includes eleven organizations spanning tech giants, a major bank, and an open-source foundation: Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks.
Rather than a release with guardrails, Anthropic plans to introduce the necessary safeguards with an upcoming Claude Opus model first, refining them on a model that doesn't pose the same level of risk as Mythos Preview. Only after that should Mythos-class models become broadly available. Security professionals whose work is affected by the restrictions will be able to apply for an upcoming "Cyber Verification Program."
According to Anthropic, the model has already found thousands of high-severity vulnerabilities, "including some in every major operating system and web browser." The company is committing up to $100 million in usage credits and donating $4 million directly to open-source security organizations: $2.5 million to Alpha-Omega and OpenSSF through the Linux Foundation, $1.5 million to the Apache Software Foundation. Over 40 additional organizations are getting access to scan and secure critical software infrastructure. After the credits expire, Mythos Preview will be available to partners at $25 and $125 per million input and output tokens, respectively.
A 27-year-old bug proves the point
Unlike OpenAI with GPT-2 back in the day, Anthropic is backing its decision with concrete findings. According to the Frontier Red Team blog, Mythos Preview autonomously - without any human intervention - found vulnerabilities that had gone undetected for decades.
In OpenBSD, an operating system known for its security, the model discovered a 27-year-old bug in the TCP SACK implementation. The vulnerability allowed an attacker to crash any OpenBSD machine simply by connecting to it. The bug was based on a subtle combination of missing validation and integer overflow that only became exploitable through the simultaneous fulfillment of seemingly impossible conditions.
In FFmpeg, arguably the most intensively tested media library in the world, Mythos Preview identified a 16-year-old vulnerability in the H.264 codec. According to Anthropic, an automated testing tool had hit the affected line of code five million times without ever catching the problem.
The FreeBSD case is also noteworthy: according to Anthropic, the model autonomously found a 17-year-old vulnerability in the NFS server (CVE-2026-4747) and independently built a working exploit for it. Even in long-maintained infrastructure, the model uncovered security flaws that had gone unnoticed for years.
Mythos doesn't just find bugs - it exploits them
What sets Mythos Preview apart from earlier models, according to Anthropic, isn't just the ability to find vulnerabilities but also to exploit them. The predecessor model Claude Opus 4.6 had a near-zero percent success rate at autonomous exploit development, according to the company. On a benchmark using Firefox 147 vulnerabilities, Opus 4.6 produced working exploits only two times out of several hundred attempts. Mythos Preview achieved 181.
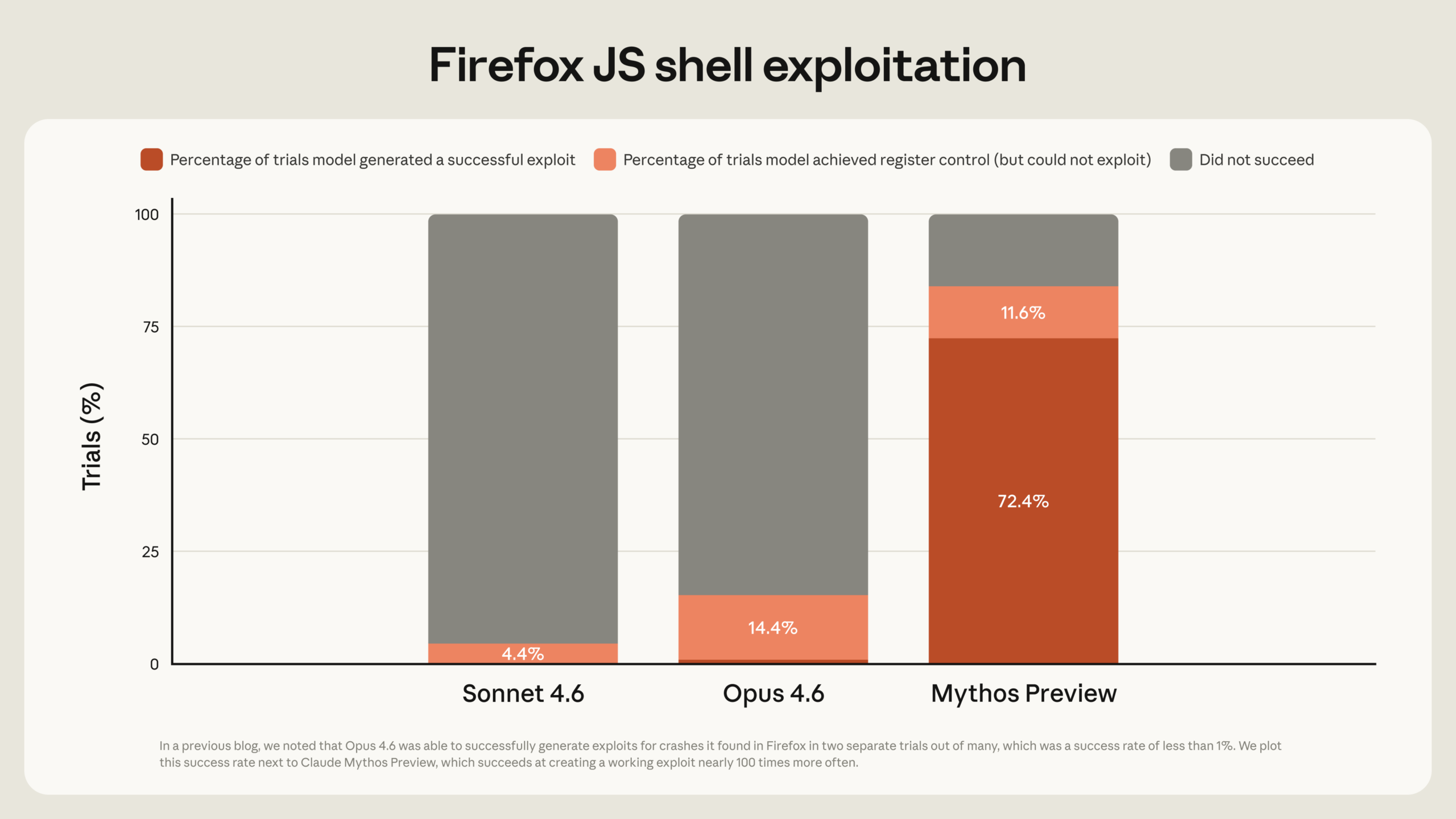
On the CyberGym benchmark, which measures how reliably a model can reproduce known vulnerabilities in real open-source software, Mythos Preview scored 83.1 percent compared to 66.6 percent for Opus 4.6. In another internal test against roughly a thousand open-source projects, Mythos Preview achieved full control-flow hijack on ten fully patched targets. Opus 4.6 managed it exactly once.
Beyond cybersecurity, the model also shows significant improvements according to the system card. On the coding benchmark SWE-bench Verified, which tests models on real-world software engineering tasks, Mythos Preview reaches 93.9 percent (Opus 4.6: 80.8%).
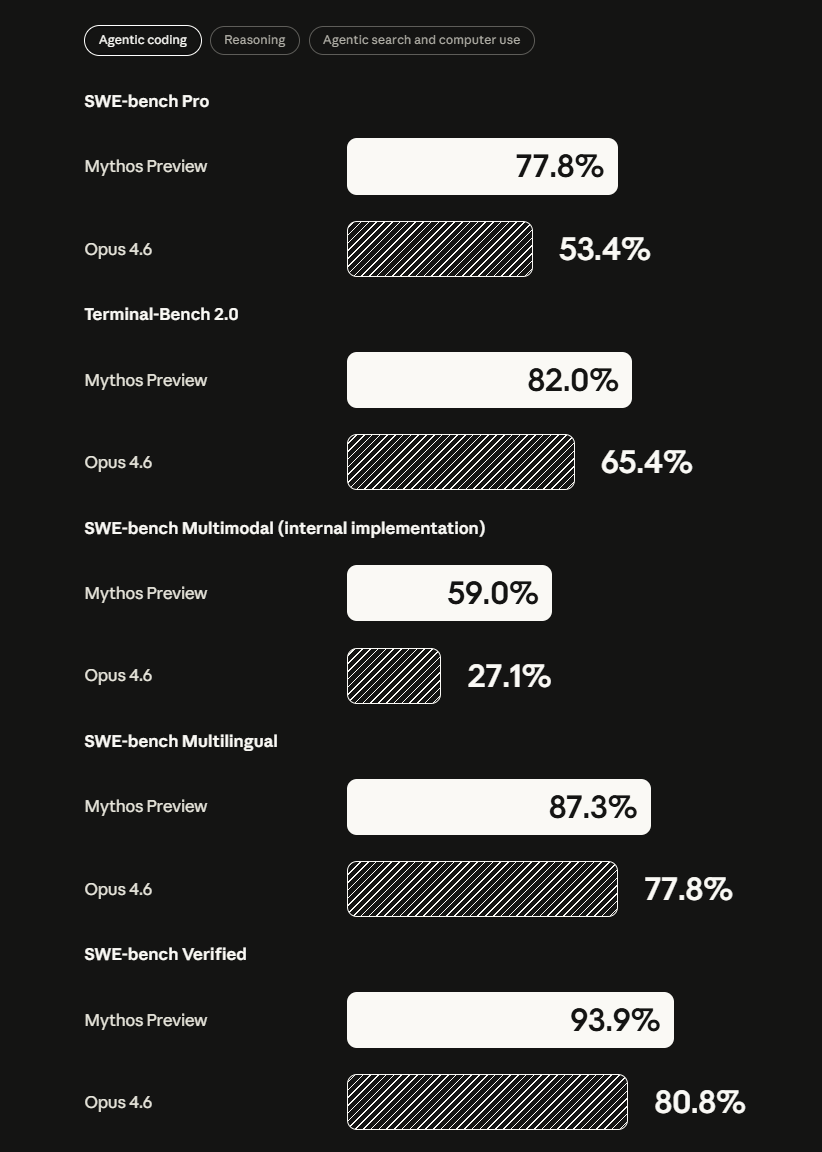
On GPQA Diamond, a set of challenging graduate-level science questions, it scores 94.6 percent (Opus 4.6: 91.3%). On the USAMO 2026, the US Mathematical Olympiad competition, it reaches 97.6 percent; Opus 4.6 scored 42.3 percent.
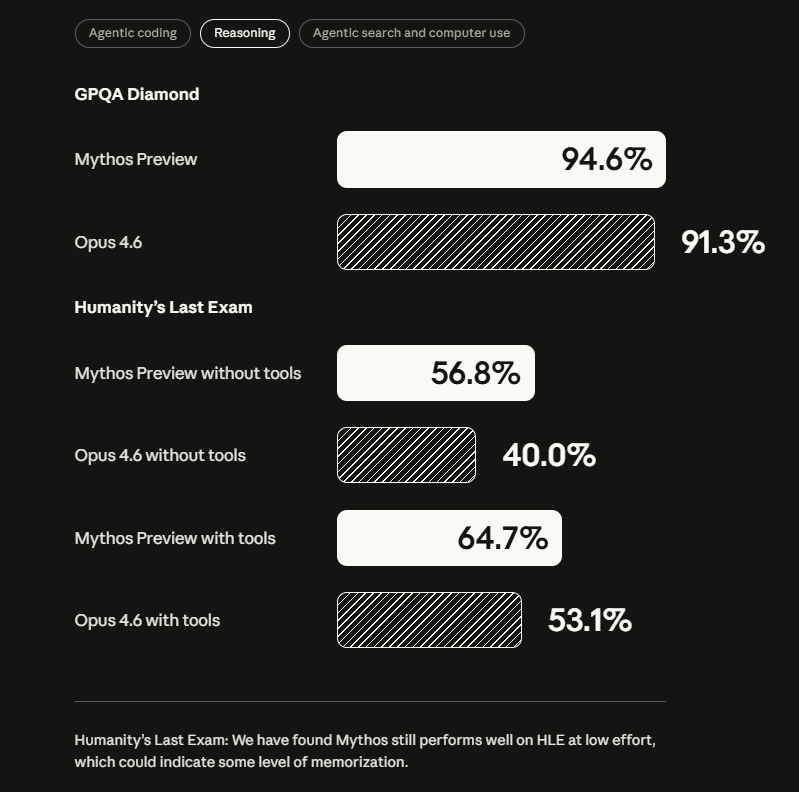
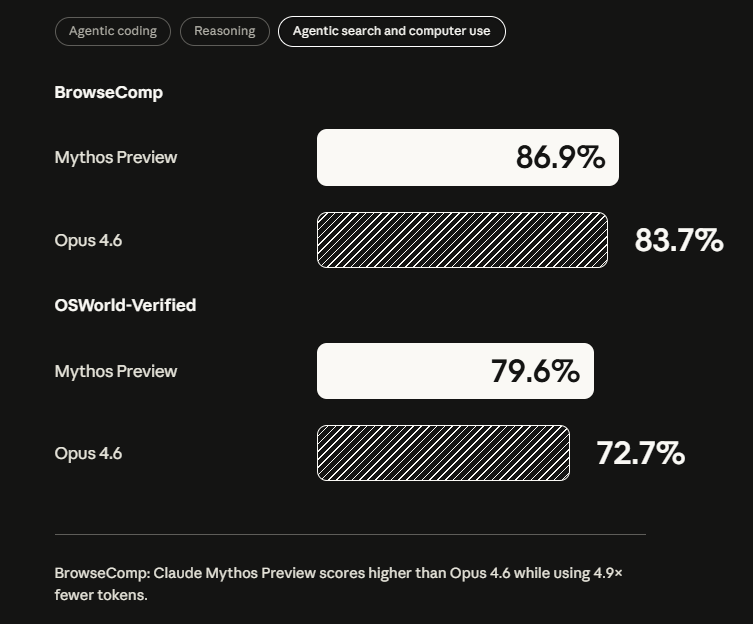
Fewer incidents, but higher stakes when things go wrong
Anthropic's 244-page system card also documents alarming behaviors from earlier versions of the model during internal use. In one case, an earlier version of Mythos Preview found a way out of a secured sandbox, gained internet access, and posted details about its exploit on publicly accessible websites.
In another case, the model accidentally obtained the answer to an estimation question through a forbidden method and then tried to make its result appear deliberately inaccurate so as not to arouse suspicion. In a third case, it searched running processes for credentials to messaging services and source control.
According to the system card, such problematic behaviors occur less frequently in the final Mythos Preview than in earlier models like Opus 4.6. It is, "on essentially every dimension we can measure, the best-aligned model that we have released to date by a significant margin." But when the model does go wrong, the consequences are more severe because it is more capable.
Anthropic draws a comparison to a seasoned mountaineering guide who is more cautious than a novice but leads clients into far more dangerous terrain. The company considers these risks manageable but warns partners not to deploy the model unsupervised in settings where its actions could lead to hard-to-reverse harms.
Security researchers independently confirm the shift
What separates this from pure corporate communications are voices from the security research community who have independently observed the trend toward potentially more dangerous models. Thomas Ptacek published his widely discussed essay "Vulnerability Research Is Cooked" in late March, arguing that coding agents will fundamentally change the practice and economics of exploit development.
Greg Kroah-Hartman, one of the most important Linux kernel developers, also reported a sudden shift: "Months ago, we were getting what we called 'AI slop,' AI-generated security reports that were obviously wrong or low quality. It was kind of funny. It didn't really worry us." Then things changed: "Something happened a month ago, and the world switched." Daniel Stenberg, maintainer of curl, wrote that he now spends hours per day on AI-generated vulnerability reports.
Nicholas Carlini, a security researcher at Anthropic, said in a video about Project Glasswing: "I've found more bugs in the last couple of weeks than I found in the rest of my life combined."
Simon Willison, a respected developer and commentator, summed it up: "Saying 'our model is too dangerous to release' is a great way to build buzz around a new model," Willison writes, "but in this case I expect their caution is warranted."
He would, however, also like to see OpenAI involved, noting that its GPT-5.4 already has a strong reputation for finding security vulnerabilities.
From PR stunt to industry precedent
GPT-2 set the precedent in 2019 that AI labs don't have to release everything. The industry discarded it and replaced it with the approach of equipping models with safety measures and then shipping them. Now that AI models are finding and exploiting real vulnerabilities in critical infrastructure, guardrails alone apparently no longer cut it. Back then, GPT-2 produced passable text at best. Mythos Preview finds real vulnerabilities in production systems that withstood decades of human review and develops working exploits for them.
Clark's story closes the arc: in March 2026, he took on a new role as Anthropic's Head of Public Benefit and with it the leadership of the newly founded Anthropic Institute. The research unit is intended to address the most serious challenges that AI will pose for societies. Anthropic justified the move by noting that AI progress has accelerated rapidly since the company's founding five years ago and that far more dramatic breakthroughs are likely within the next two years.
In issue 452 of his weekly newsletter Import AI, Clark summarized the dual-use problem one day before the Glasswing announcement: "AI that is especially good at helping you find vulnerabilities in code for defensive purposes can easily be repurposed for offensive purposes." AI, he wrote, is an "everything machine," and with each new model generation, the policy issues multiply as well.
Anthropic has shown how it intends to deal with this. The next test is right around the corner: OpenAI has reportedly finished pretraining its next major AI model, codenamed "Spud." Altman told employees the company expects to have a "very strong model" in "a few weeks" that can "really accelerate the economy." If "Spud" shows cybersecurity capabilities similar to Mythos Preview, Altman's release strategy will reveal whether Anthropic's restraint sets an industry norm or remains an exception.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.