Gemini 2.5 Flash-Lite is the fastest and most cost-effective model in Google's Gemini lineup
Google has officially launched the stable versions of its Gemini 2.5 Flash and Pro models, marking them as production-ready after a successful preview phase.
Both models have already posted strong results in industry benchmarks, and according to anecdotal reports and our own experience, this performance carries over into real-world use.
Alongside these releases, Google is previewing a new variant: Gemini 2.5 Flash-Lite. The company describes Flash-Lite as the fastest and most cost-effective model in the Gemini 2.5 lineup so far.
Developers can now access Flash-Lite in Google AI Studio and Vertex AI, with the stable Flash and Pro models also available through these platforms and the Gemini app. Google Search uses custom versions of Flash and Flash-Lite as well.
Flash-Lite: Speed and efficiency at a lower price point
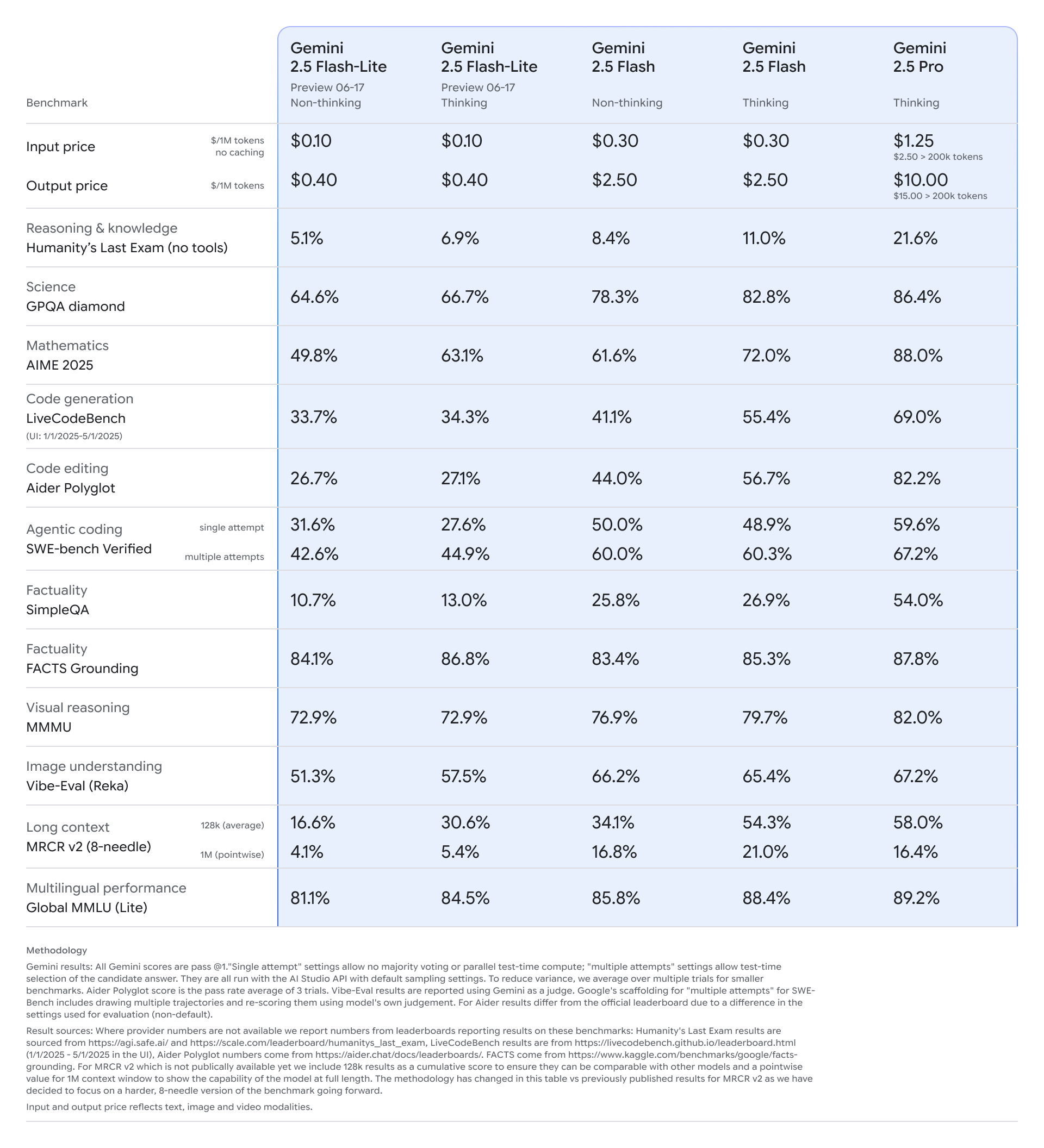
According to Google, Gemini 2.5 Flash-Lite outperforms its predecessor (2.0 Flash-Lite) in benchmarks for programming, math, science, logical reasoning, and multimodal tasks. In tests like GPQA (science), AIME (math), and LiveCodeBench (code generation), Flash-Lite scores substantially higher than earlier Lite models and even closes the gap with larger models in some areas.
Flash-Lite pricing is the same for both the standard and "Thinking" modes: $0.10 per million input tokens and $0.40 per million output tokens. However, "Thinking" models generate significantly more tokens—so-called reasoning traces—to improve results, which means their actual usage costs are typically higher.
Google says Gemini 2.5 Flash-Lite is especially well-suited for high-volume, low-latency tasks like translation and classification. Benchmark results support this, with Flash-Lite posting 86.8% in FACTS Grounding and 84.5% in Multilingual MMLU. Visual benchmarks are also strong, with scores of 72.9% on MMMU and 57.5% for image understanding.
Like the other Gemini 2.5 models, Flash-Lite supports multimodal input, tool integrations such as Google Search and code execution, and context windows up to one million tokens.
The entire Gemini 2.5 family is designed for hybrid reasoning, aiming to balance high performance with low cost and latency. Google positions these models on the Pareto front, optimizing for both efficiency and capability.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.