
Google's new text-to-image model "Muse" generates high-quality images at record speed. It is also supposed to represent texts and concepts in images more reliably.
Researchers at Google Research introduce "Muse," a Transformer-based generative image AI that produces images on par with current models but is said to be "significantly more efficient" than existing diffusion models such as Stable Diffusion and DALL-E 2 or autoregressive models such as Google Parti.
Similar quality, but much faster
Muse performs equally well as Stable Diffusion 1.4 and Google's in-house competitors Parti-3B and Imagen in terms of quality, variety, and text alignment of generated images.

However, Muse is significantly faster. With a generation time of 1.3 seconds per image (512 x 512), the image AI clearly outperforms the fastest image AI system, Stable Diffusion 1.4, with 3.7 seconds.

The team achieved the speed advantage using a compressed discrete latent space and parallel decoding. For text comprehension, it uses a frozen T5 language model that is pre-trained on text-to-text tasks. According to the team, Muse fully processes a text prompt rather than focusing only on particularly salient words.
Compared to pixel-space diffusion models, such as Imagen and DALL-E 2, Muse is significantly more efficient due to the use of discrete tokens and requiring fewer sampling iterations; compared to autoregressive models, such as Parti, Muse is more efficient due to the use of parallel decoding. The use of a pre-trained LLM enables fine-grained language understanding, translating to high-fidelity image generation and the understanding of visual concepts such as objects, their spatial relationships, pose, cardinality etc
From the paper
The new architecture enables a range of image editing applications without additional fine-tuning or inversion of the model. Within an image, objects can be replaced or modified by prompt alone, without masking.

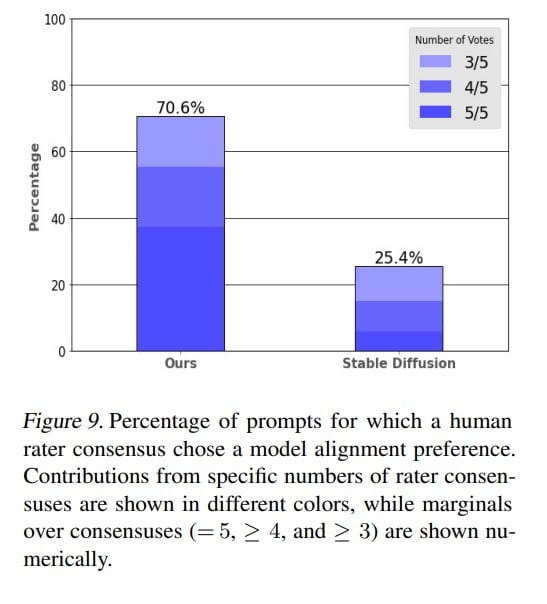
In an evaluation by human testers, Muse's images were rated as better suited to text input than those of Stable Diffusion 1.4 in around 70 percent of cases.
Muse is also said to be above average at incorporating predefined words into images, such as a T-shirt that says "Carpe Diem". In addition, Muse is said to be precise in composition, i.e. it displays predefined image elements in the prompt in more exact numbers, positions, and colors. This often doesn't work with current image AI systems.
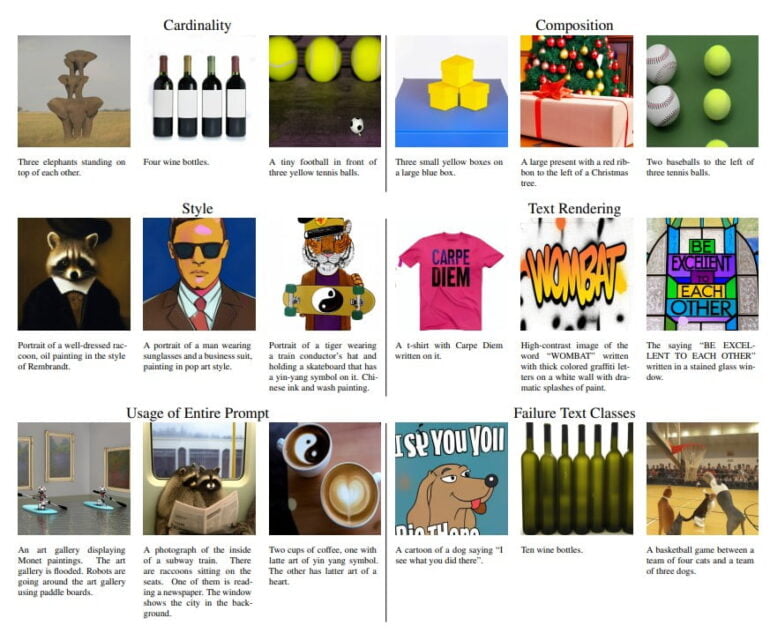
More image examples are available on the project website. The researchers and Google itself have not yet commented on a possible release of the image model to compete with OpenAI's DALL-E 2 or Midjourney. Currently, only Google's Imagen is available in a beta version limited to the US.

As is common with scientific work on AI systems for language and images these days, the Muse team points out that depending on the use case, there is the "potential for harm," such as reproducing social biases or spreading misinformation. For this reason, the team refrains from publishing the code and a publicly available demo. In particular, the team notes the risk of using image AI models to generate people, humans, and faces.





