Meta researchers develop method to make AI models "think" before answering
Scientists from Meta, UC Berkeley, and NYU have created a new technique to improve how large language models (LLMs) approach general tasks. Called "Thought Preference Optimization" (TPO), the method aims to make AI systems consider their responses more carefully before answering.
"We argue that “thinking” should have broad utility," the researchers explain. "For example, in a creative writing task, internal thoughts can be used to plan overall structure and characters."
This approach differs from previous "chain-of-thought" (CoT) prompting techniques, which have mainly been used for math and logic tasks. The researchers cite OpenAI's new o1 model as support for their thesis that thinking can benefit a wider range of tasks.
Training without additional data
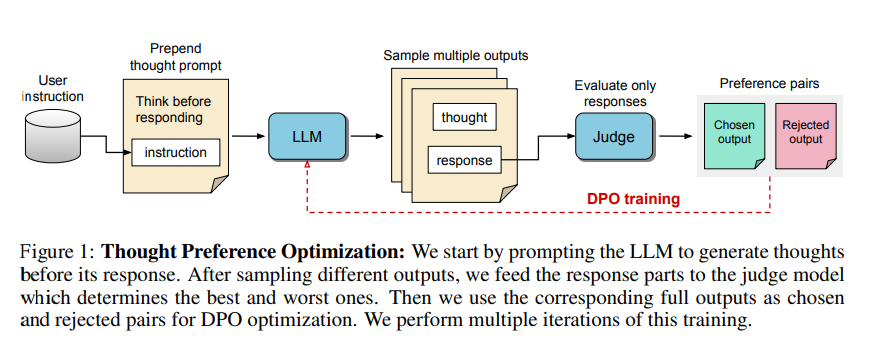
TPO overcomes the challenge of limited training data containing human thought processes. It works by:
1. Asking the model to generate thought steps before answering
2. Creating multiple outputs
3. Using an evaluator model to assess only the final answers
4. Training the model through preference optimization based on those evaluations
The thought steps themselves are not directly evaluated - only their results. The researchers hope better answers will require improved thought processes, allowing the model to implicitly learn more effective reasoning.
This method differs significantly from OpenAI's approach with the o1 model. While the exact training process for o1 is unclear, it likely involved high-quality training data with explicit thought processes. Additionally, o1 actively "thinks" by outputting its thought steps as text for analysis.
Improvements across some categories
When tested on benchmarks for general instruction following, a Llama 3 8B model using TPO outperformed versions without explicit reasoning. On the AlpacaEval and Arena-Hard benchmarks, TPO achieved win rates of 52.5% and 37.3% respectively.
The improvements weren't limited to traditional reasoning tasks. TPO showed gains in areas not typically associated with explicit thinking, such as general knowledge, marketing, or health.
"This opens up a new opportunity to develop Thinking LLMs aimed at general instruction following rather than specializing in more narrow technical fields," the researchers conclude.
However, the team notes the current setup isn't suitable for math problems, where performance actually declined compared to the baseline model. This suggests that different approaches may be needed for highly specialized tasks.
Future work could focus on making the length of thoughts more controllable and investigating the effects of thinking on larger models.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.