
Microsoft's generative AI model VALL-E converts text into speech. It uses methods derived from large language models.
Text-to-speech systems have recently become more powerful thanks to neural networks. In audio synthesis, they convert phonemes into spectrograms, process them in their network, and then generate the final waveforms.
For training, current models usually require high-quality recordings. Low-quality recordings collected from the Internet lead to poor results.
Furthermore, the quality of the generated speech decreases significantly for speakers that are not part of the training data set. To improve performance in such zero-shot scenarios, researchers use methods like speaker adaption or speaker encoding. They require additional fine-tuning or various pre-designed features.
Microsoft VALL-E learns from GPT-3 & Co.
Researchers at Microsoft are now demonstrating VALL-E, a text-to-speech model based on the successful recipe of large language models. "Instead of designing a complex and specific network for this problem, the ultimate solution is to train a model with large and diverse data as much as possible," the paper says.
VALL-E was trained with 60,000 hours of English speech from 7,000 speakers. According to the team, that's more than 100 times the amount of data previously used in the field. Microsoft is using the massive LibriLight dataset, which the team transcribed with AI.
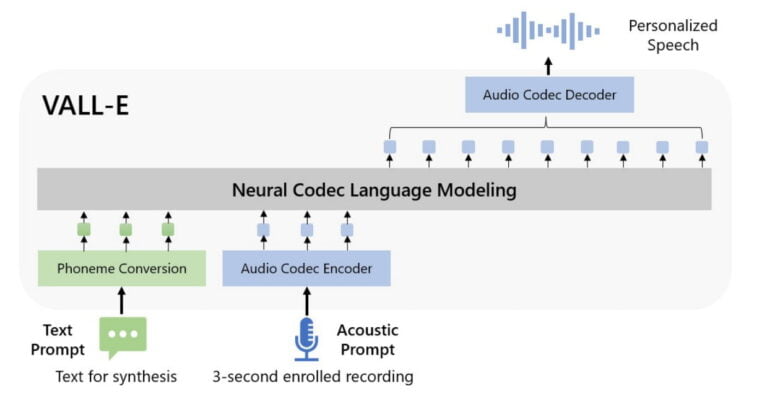
VALL-E processes a combination of text prompts and three-second acoustic prompts, which are directly represented as acoustic tokens in the network. The acoustic tokens in the network are then converted into waveforms by an audio codec decoder. VALL-E, therefore, does not take the detour via the usual spectrograms.
VALL-E leverages the advantages of large language models
In their tests, the researchers show that VALL-E can generate text prompts using the voice specified in the acoustic prompt.
Acoustic prompt
Text prompt
"Her husband was very concerned that it might be fatal."
VALL-E
The model also inherits aspects of the audio snippet: The noisiness of a phone recording also comes through in the synthesized continuation.
Acoustic prompt
Text prompt
"Um we have to pay this security fee just in case she would damage something but um."
VALL-E
In addition, the model adopts voice pitches influenced by emotions, such as that of an angry speaker.
Acoustic prompt
Text prompt
"We have to reduce the number of plastic bags."
VALL-E
When the acoustic prompt has reverberation, VALL-E could synthesize speech with reverberation as well, whereas the baseline outputs clean speech. Our explanation is that VALL-E is trained on a large-scale dataset consisting of more acoustic conditions than the data used by the baseline, so VALL-E could learn the acoustic consistency instead of a clean environment only during training.
[...]
In addition, we find VALL-E could preserve the speaker’s emotion and acoustic environment of the acoustic prompt in synthesis
From the paper
This is interesting because VALL-E was not explicitly trained to e.g. integrate emotions into generated voices. According to the researchers, the model shows some emergent capabilities and can learn in context - just like large language models.
More audio examples are available on GitHub. The code is not available.



