
MineDojo is meant to lay the groundwork for the future of artificial intelligence - in Minecraft. The researches hope, it helps the engineering of embodied AI agents that explore worlds and constantly improve themselves.
In the summer of 2022, scientists founded the Center for Research on Foundation Models (CRFM) at the Stanford Institute for Human-Centered Artificial Intelligence (HAI).
The term "foundation model" was proposed by Stanford researchers for any AI model "that is trained on broad data (generally using self-supervision at scale) that can be adapted (e.g., fine-tuned) to a wide range of downstream tasks".
Crucially, models such as OpenAI's GPT-3 established a "paradigm for building AI systems" in the months and years following release. The most important features of foundation models, they said, were the emergence of the model and its capabilities - some of which were not anticipated - and the homogenization of their methods, which are used in many domains apart from text.
"GPT3 is powerful but blind"
Despite impressive capabilities, models like GPT-3 still have many limitations and are mostly restricted to one domain. As a result, some researchers are investigating how to build on the foundation: Methods such as chain-of-thought prompting, Python access, SayCan robot control, or linking to a physics simulator are just a few of the approaches that extend the abilities of large language models.
Researchers from Nvidia, Caltech, Stanford, Columbia, SJTU, and UT Austin see an alternative future for foundation models, "GPT3 is powerful but blind. The future of Foundation Models will be embodied agents that proactively take actions, endlessly explore the world, and continuously self-improve," said Nvidia researcher Linxi Fan on Twitter.
GPT3 is powerful but blind. The future of Foundation Models will be embodied agents that proactively take actions, endlessly explore the world, and continuously self-improve. What does it take? In our NeurIPS Outstanding Paper "MineDojo", we provide a blueprint for this future:? pic.twitter.com/YZps22n9pA
- Jim (Linxi) Fan (@DrJimFan) November 23, 2022
However, this requires new approaches, according to the researchers. AI agents have made great strides in specific domains, such as Atari or Go games. But they can not generalize across a wide range of tasks and skills yet.
Three main pillars are needed for the emergence of generalist embodied agents, the researchers write in a new paper.

"First, the environment in which the agent acts needs to enable an unlimited variety of open-ended goals."
Natural evolution is enabled by Earth's infinitely diverse ecological conditions. This process has been going on incessantly for billions of years. Today's training algorithms for AI agents, on the other hand, showed no new progress after convergence in narrow environments, the researchers state.
"A large-scale database of prior knowledge is necessary to facilitate learning in open-ended settings."
Just as humans often learn from the Internet, agents should be able to gather practical knowledge too, the team writes. That's because, in a complex world, it would be extremely inefficient for AI agents to learn from scratch via trial and error. Sources could include large amounts of video demos, multimedia tutorials, and forum discussions.
"The agent’s architecture needs to be flexible enough to pursue any task in open-ended environments, and scalable enough to convert large-scale knowledge sources into actionable insights."
This requirement motivates the development of an agent that relies on natural language task prompts and uses the Transformer pre-training paradigm to effectively internalize knowledge from multimodal sources. A sort of "embodied GPT3", Fan said.
MineDojo is a training toolkit for Minecraft AIs
The team is bringing these ideas together with MineDojo, an open framework for embodied agent research. MineDojo includes a simulator suite based on Minecraft, an extensive Internet database, and a basic model for agents.
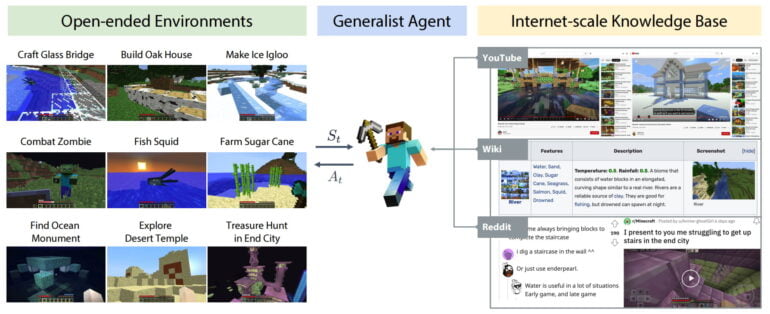
Unlike alternative Minecraft environments for AI research, such as MineRL, MineDojo supports versatile visual inputs such as RGB, voxel, LIDAR, and GPS. It includes all worlds of Minecraft (Overworld, Nether, End) and includes over 3,000 tasks. MineDojo is thus one of the largest agent benchmarks.
One class of tasks is easy to evaluate and stems from the four categories survival, harvesting, tech tree, or combat. They contain tasks such as "shearing sheep to gain wool". In addition, there are creative tasks that do not have well-defined or easily-automated success criteria. These can be tasks like "Build a haunted house with zombies in it" or "Race a pig." The environment, weather, and lighting can also be customized in detail.

In addition to the simulator suite, the team is releasing a gigantic multimodal Minecraft knowledge base: MineDojo offers an extensive collection of more than 730,000 YouTube videos with timed transcripts, more than 6,000 wiki pages, and more than 340,000 Reddit posts with multimedia content. The database is intended to serve as training material for new AI agents.
MineDojo team unveils its Minecraft agent
The team is also providing its own AI agent for Minecraft. The researchers are taking their cue from OpenAI's CLIP and using Minecraft videos from YouTube to train MineCLIP, a contrastive video-language model that links natural language subtitles to associated video segments.
MineCLIP computes the correlation between an open-vocabulary language goal string and a 16-frame video snippet from the YouTube-Database. The learned correlation score is used as an "open-vocabulary, massively multi-task reward function for RL training". The agent thus learns to perform actions following text prompts.
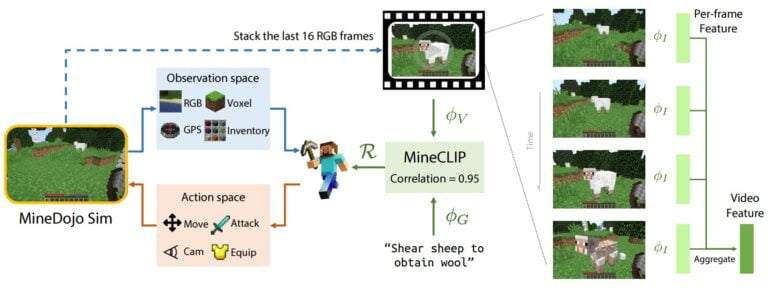
The quality of the reward signal provided by the fully trained MineCLIP is so high that the difference between the noisy YouTube video and the images rendered in the simulator is not relevant. In addition, it eliminates the need to manually engineer reward functions for each and every MineDojo task, the paper states.
Particularly in creative tasks where there is no simple success criterion, MineCLIP additionally serves a dual role as an automated scoring metric that can assess, for example, whether a house was built with a pool and matches well with human scores, the researchers say.
MineCLIP is just the beginning
In a 12-task test, the MineCLIP-trained agent solved most of these tasks and achieved competitive performance to agents trained with carefully designed reward models.
In some tasks, MineCLIP outperformed other agents, with up to a 73 percent higher success rate. The agent also performed relatively well in open-ended creative tasks.
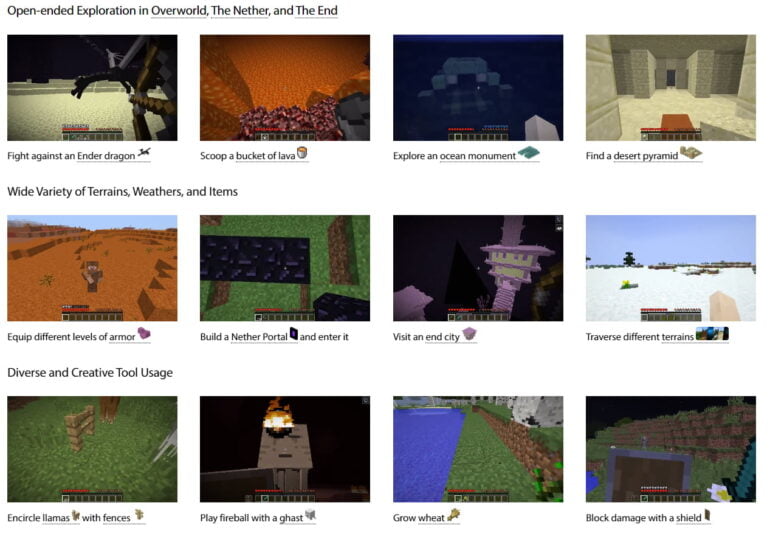
MineCLIP agents can also better deal with invisible terrain, weather, and lighting, the researchers write. If they have already been trained to perform the twelve tasks, they can generalize to some degree to new variations of those tasks, such as hunting a new species of animal in Minecraft.
The researchers emphasize that MineCLIP is just one of many ways to use the MineDojo database. For instance, MineCLIP does not make use of the Wiki and Reddit content that is also available - but these also hold great potential for new algorithms, they write in their paper.
The approach presented also does not use detailed guidance. This is an idea that is used, among others, in the previously mentioned SayCan and is a possible idea for future systems, according to the team.
MineCLIP and OpenAI's Video PreTraining.
According to Fan, the agent shown is a small step toward the vision of an "embodied GPT3." He said MineCLIP serves as a "foundation reward model" that can be inserted into any reinforcement learning algorithm. OpenAI's Video PreTraining (VPT) is therefore a complementary approach and can be fine-tuned with MineCLIP to solve language-conditioned open-ended tasks.
VPT also relies on video training. But while MineCLIP learns from video and text transcription, VPT learned from video and game input: OpenAI collected 70,000 hours of YouTube footage of Minecraft, plus another 2,000 hours of gameplay including keyboard and mouse input data.
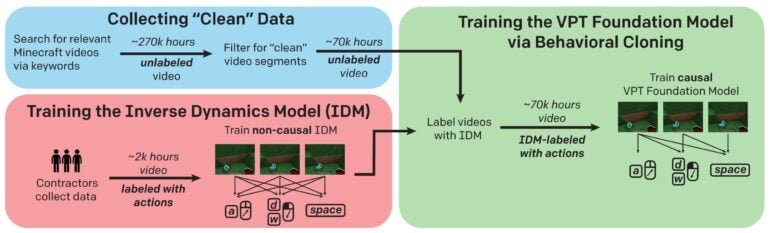
Using 2,000 hours of video, OpenAI trained an Inverse Dynamics Model (IDM) that could then predict YouTube video inputs. This resulted in a huge dataset of more than 70,000 hours of video, including keyboard and mouse input data, for training the VPT foundation model.
This input data is valuable for algorithms that learn to mimic human behavior, and the method developed with VPT could theoretically be used for any type of computer interaction for which there is enough video.
OpenAI also sees the benefits of text training: in the VPT paper, the company describes a test in which it processed subtitles alongside videos, as these are often directly related to the content of the video - a fact that MineCLIP has now exploited.
The unusual effectiveness of data
Both systems clearly show a trend for AI agents: Similar to natural language processing or image analysis and generation, huge amounts of data allow foundation models that can then learn new tasks by fine-tuning.
For example, OpenAI used VPT to train an AI agent to make a diamond pickaxe in ten minutes. According to OpenAI, this is at about the average human level.
Whether the data and scaling approach is sufficient for the MineDojo team ideas will now have to be seen. If their ideas are right, we could soon be looking at embodied, generalizing AI agents with a Minecraft world model - a kind of trial run for more complex systems that can operate in our world.
More information about MineDojo is available on the MineDojo project page. The code, data and more are available on Github.




