Mistral's Saba model brings cultural awareness to language models
Mistral AI has introduced Saba, a specialized language model designed to better understand the linguistic and cultural nuances of the Middle East and Southeast Asia.
While most large language models take a one-size-fits-all approach, Saba focuses specifically on capturing the subtle cultural contexts and language patterns unique to these regions.
The model contains 24 billion parameters - notably smaller than many competitors - but Mistral AI says it delivers superior accuracy and speed at a lower cost. The architecture likely mirrors that of their recent Mistral Small 3 model.
This efficiency means Saba can run on less powerful systems, achieving speeds over 150 tokens per second even on single-GPU setups. The company suggests this could pave the way for even more specialized regional adaptations.
A focused approach to language and culture
Saba excels at handling Arabic and Indian languages, with particular strength in South Indian languages like Tamil and Malayalam. This broad language coverage serves the interconnected regions of the Middle East and Southeast Asia.
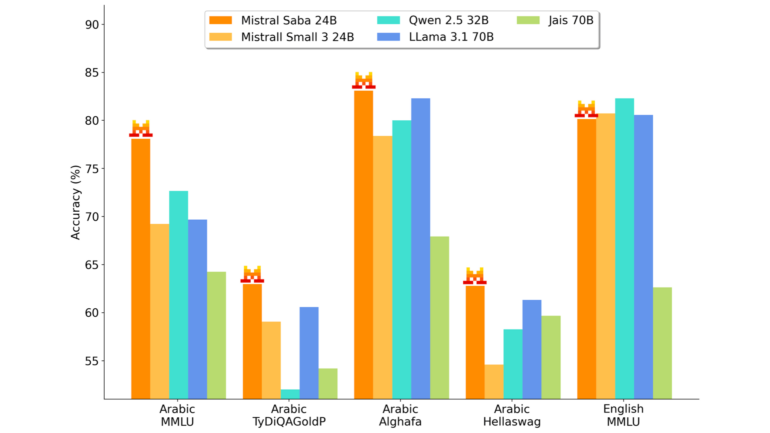
The model is already powering real-world applications, according to Mistral, from Arabic-language virtual assistants that can hold natural conversations to specialized tools for energy, financial markets, and healthcare. Its better understanding of local idioms and cultural references also makes it effective for generating region-specific content.
You can access Saba through either a paid API or local deployment on their infrastructure. Like other Mistral models, it isn't open source, and the exact development process remains private. The company likely started by building a dataset optimized for their target languages.
Other organizations are pursuing similar goals. The OpenGPT-X project released Teuken-7B, trained on roughly 50% non-English data. OpenAI has developed a Japanese-specific GPT-4 model, while the EuroLingua project focuses on European languages, and the German association Laion created LeoLM for German.
Large language models learn by processing massive text datasets to form statistical relationships between words and sentences. For example, 93 percent of GPT-3's training data was in English, according to research. While this creates broad language understanding, it often misses subtle nuances that native speakers recognize - precisely the gap Saba aims to fill.
However, language optimization doesn't guarantee superior performance. A model's base capabilities matter more than language-specific fine-tuning.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.