MLPerf: Nvidia Hopper GPU dominates competition

Nvidia's Hopper H100 GPU makes its debut in the MLPerf benchmark. The new AI accelerator leaves the competition far behind. Qualcomm however shows strong performance in edge computing.
Hardware manufacturers and service providers compete with their AI systems in the MLPerf benchmark. The test is managed by MLCommons and aims at a transparent comparison of different chip architectures and system variants.
MLPerf publishes different results for training and for inference of AI models each year. Now the results of this year's "MLPerfTM Inference v2.1" benchmark have been published.
With 21 participants, 5,300 performance results, 2,400 energy measurements, a new division, a new object recognition model (RetinaNet), and a new Nvidia GPU, the latest round sets new records.
Nvidia's Hopper GPU shows strong performance
In the MLPerf benchmark, Nvidia is the only manufacturer to participate in all six model categories in the closed division (ResNet-50, RetinaNet, RNN-T, BERT-Large 99%, BERT-Large 99.9%, DLRM). This time it also shows its brand new Hopper GPU H100 in the preview category. It should be available at the end of the year.
Nvidia presented the new H100 at the GTC 2022 in March. Built for AI calculations, the GPU is the successor to Nvidia's A100 and relies on TSMC's 4nm process and HBM3 memory. The H100 GPU comes with 80 billion transistors, delivers 4.9 terabytes of bandwidth per second, and relies on PCI Express Gen5.
Nvidia promises significantly faster inferencing compared to the A100. For FP32, the H100 GPU delivers 1,000 TeraFLOP of performance, and for FP16, 2,000 TeraFLOP. In addition, the H100 comes with a new transformer engine in which the fourth-generation tensor cores dynamically switch between FP8 and FP16 precision with specialized software. This should allow large language models in particular to be trained much faster.
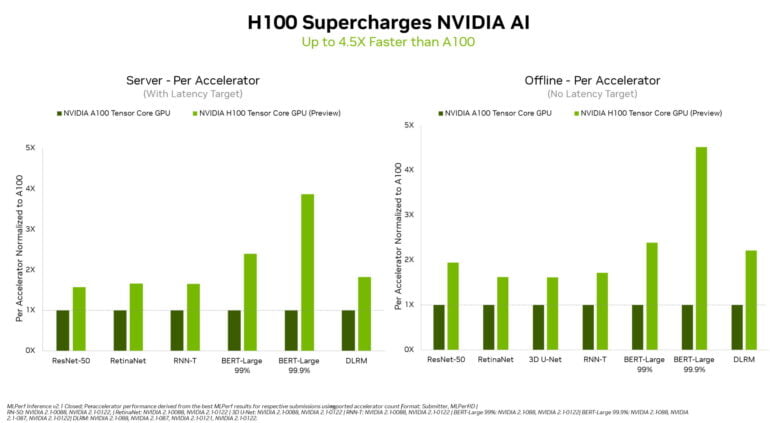
In the now published results, Nvidia's new GPU clearly pushes itself ahead of the A100 and all other participants. Depending on the benchmark, the H100 achieves up to 4.5 times higher speed than A100-based systems.
This jump is also possible due to the Transformer Engine, which intelligently switches the accuracy, for example, in the inference of BERT-Large. Further performance jumps of the H100 in future benchmarks are possible: through software improvements, Nvidia has increased the performance of the A100 by 6x since the first entry in MLPerf.
Qualcomm catches up, Intel shows Sapphire Rapids
Meanwhile, the successful A100 GPU still maintains its lead over other manufacturers' products in almost all categories. The only exception is Qualcomm's CLOUD AI 100 accelerator, which managed to push ahead of Nvidia's A100 in some divisions (ResNet-50 and BERT-Large 99,9 % models) despite low power consumption.
Besides the A100, however, Nvidia also entered the race with Orin, also a low-power SoC. Unlike Qualcomm's chip, Orin competed in all edge computing benchmarks and thus won the most benchmarks overall with 50% higher energy efficiency compared to its debut in April.
In addition to Nvidia and Qualcomm, Intel showed the first look at Sapphire Rapids, Intel's first chiplet design for server CPUs. In addition, AI startups Biren, Moffet AI, Neural Magic, and Sapeon participated in the benchmark.
AI News Without the Hype – Curated by Humans
Subscribe to THE DECODER for ad-free reading, a weekly AI newsletter, our exclusive "AI Radar" frontier report six times a year, full archive access, and access to our comment section.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.