New AI training method mitigates the "lost-in-the-middle" problem that plagues LLMs

Researchers from Microsoft, Peking University, and Xi'an Jiaotong University have developed a new data-driven approach called INformation-INtensive (IN2) training that aims to solve the "lost-in-the-middle" problem in large language models (LLMs).
The lost-in-the-middle phenomenon is currently one of the biggest challenges for LLMs, where they understand information at the beginning and end of a long context but struggle to process information in the middle. This makes LLMs unreliable when evaluating large amounts of data, despite the advantage of having a large output context window.
The researchers believe that the cause of this issue is an unintentional bias in the training data. Pre-training focuses on predicting the next token based on nearby tokens, while fine-tuning often involves system instructions at the beginning of the context that heavily influence the response generation. This unconsciously introduces a position bias, suggesting that important information is always located at the beginning and end of the context.
IN2 training uses synthetic question-answer data to explicitly show the model that important information can be located at any position within the context. The long context (4K-32K tokens) is filled with many short segments (128 tokens), and the questions target information contained in these randomly placed segments.
The researchers used two types of training questions: those asking for details in one segment and those requiring the integration and inference of information from multiple segments.
Found in the middle - at least more often
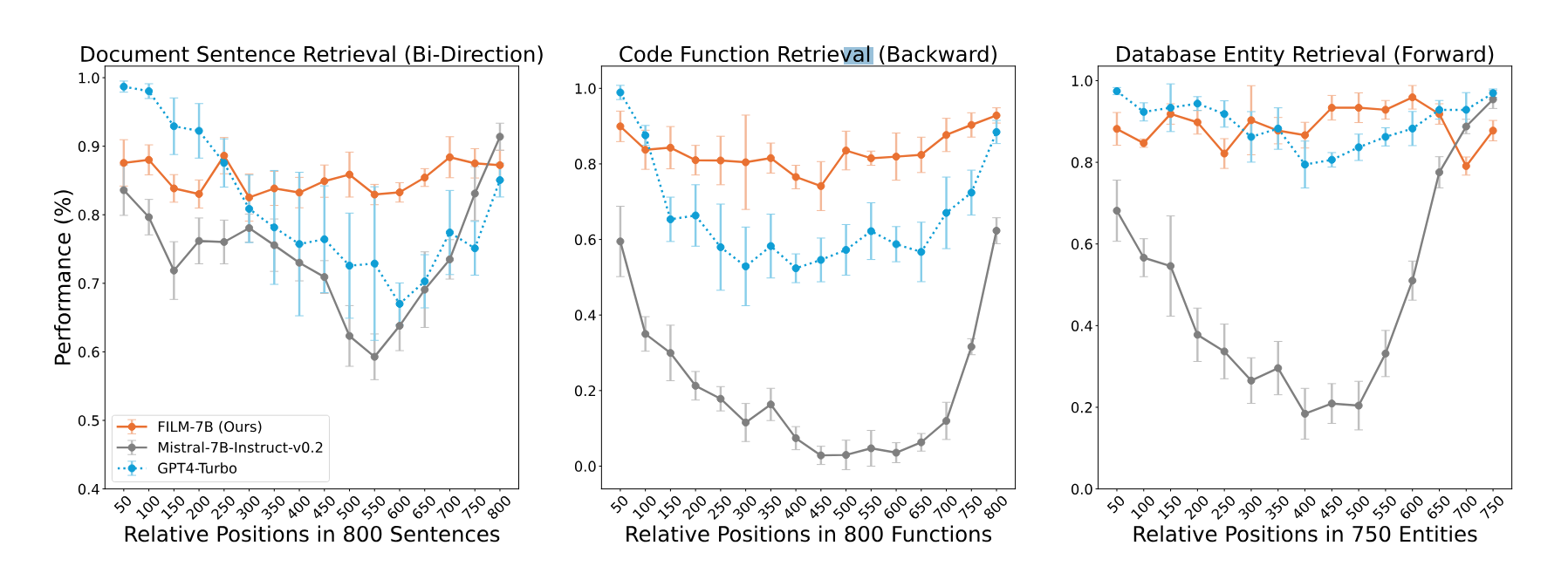
The researchers applied IN2 to Mistral-7B, resulting in FILM-7B (FILl-in-the-Middle). Tests on three new extraction tasks designed for long contexts. The tests cover different context types (document, code, structured data) and search patterns (forward, backward, bidirectional).
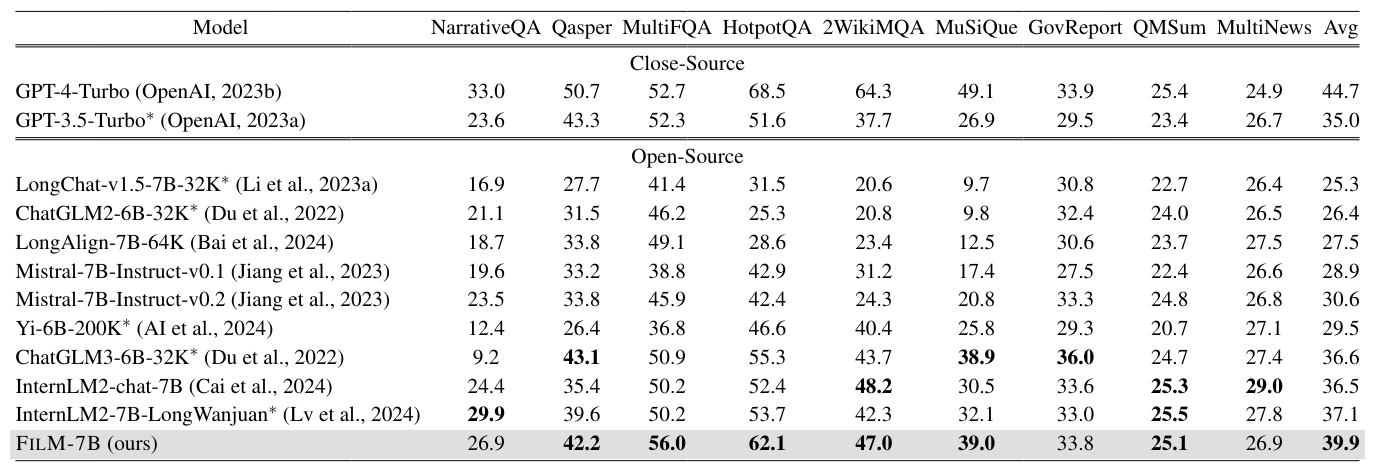
The results show that IN2 significantly reduces the "lost-in-the-middle" problem of the original Mistral model. In addition, as a much smaller model, FILM-7B achieves comparable or even more robust performance than proprietary models such as GPT-4 Turbo with 128K.
FILM-7B also shows significant improvements in real-world tasks with long contexts, such as summarizing long texts, answering questions about long documents, and reasoning about multiple documents, while maintaining its ability to perform tasks with short contexts.
However, the lost-in-the-middle problem is not solved yet, as GPT-4 Turbo remains the strongest model in the context benchmarks, despite having problems with long contexts.
The researchers also point out that the widely used "Needle in the Haystack" test misrepresents the long context capabilities of the models due to its use of familiar document-like context and simplified forward information retrieval. They propose their VAL probing approach as a more suitable method for evaluating the contextual performance of language models, since it covers different context styles and retrieval patterns for a more thorough evaluation.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.