
Nvidia and Stanford show 3D GANs that can generate even better synthetic images and, for the first time, 3D reconstructions.
Used for deepfakes, among other things, Generative Adversarial Networks now generate photorealistic images of people, animals, mountain ranges, beaches, or food. One of the most powerful systems comes from Nvidia and is called StyleGAN. However, this system and similar AI models can't generate 3D representations on current hardware.
Such 3D representations have two advantages: they help generate multiple images of a synthetic person from different angles and can also serve as the basis for a 3D model of the person.
This is because, in traditional 2D GANs, images from different angles of the same synthetic person often show changes in the representation: sometimes an ear is different, a corner of the mouth is distorted, or the eye area looks different.
Nvidia's latest StyleGAN variant StyleGAN3 achieved higher stability but is still far away from a natural result. The network doesn't store 3D information and therefore can't keep the display stable from multiple viewing angles.
Three layers instead of NeRFs and voxels
In contrast, other methods such as Google's Neural Radiance Fields (NeRFs) can learn 3D representations and subsequently generate new viewpoints with high stability in the representation.
For that, NeRFs rely on neural networks, in which an implicit 3D representation of the learned object is formed during training. The counter design to the learned implicit representation is the explicit representation of a voxel grid.
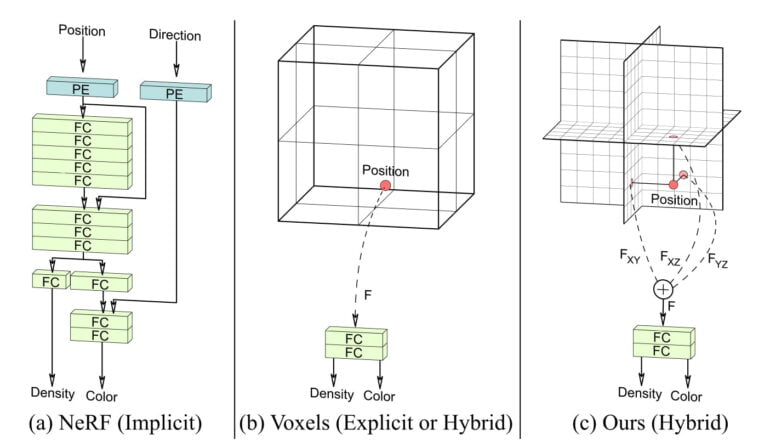
Both methods have advantages and disadvantages: Viewpoint queries to voxel grids are processed quickly; for NeRFs, these take up to several hours, depending on the architecture. Voxel grids, on the other hand, are very memory-hungry at high resolutions, while NeRFs are memory-efficient due to their implicit 3D representation as a function.
Researchers at Stanford University and Nvidia are now demonstrating a hybrid approach (Efficient Geometry-aware 3D Generative Adversarial Networks, EG3D) that combines explicit and implicit representations, making it fast and scaling efficiently with resolution.
Nvidia's 3D GAN EG3D needs only one image
The team relies on a three-plane 3D representation rather than a full voxel grid. The three-plane module is connected behind a StyleGAN2 generator mesh and stores the generator's output.
A neural renderer decodes the stored information and passes it to a super-resolution module. This scales the 128 by 128 pixel small image to 512 by 512 pixels. The images also contain the depth information represented in the three layers.
Video: via Matthew Aaron Chan
The result is a 3D GAN that can generate consistent images of, say, a person from different angles and a 3D model. EG3D can also generate a matching 3D reconstruction from a single image. In the examples shown, the quality of the results exceeds that of other GANs and even other methods such as NeRFs.
Video: via Matthew Aaron Chan
The researchers point to limitations with fine details such as individual teeth and plan to improve their AI there. They also say it's possible to swap out individual modules and retool the system to generate targeted images via text, for example.
Finally, the team warns of potential misuse of EG3D: 3D reconstruction based on a single image could potentially be used for deepfakes. More information and examples are available on the EG3D project page.





