OpenAI launches new reasoning model o3-mini for free ChatGPT and API
OpenAI has released o3-mini, its latest reasoning model that shows particular strength in STEM fields (science, mathematics, and programming) while being both faster and more capable than its predecessor.
OpenAI says external experts preferred o3-mini's answers 56% of the time and found 39% fewer serious errors on complex questions. The model also shows better results across languages. In coding tasks, it achieves up to 49.3% success on benchmarks like SWE-bench Verified.
"While OpenAI o1 remains our broader general knowledge reasoning model, OpenAI o3-mini provides a specialized alternative for technical domains requiring precision and speed," OpenAI says.
The model introduces three "reasoning-effort" settings - low, medium, and high - letting developers balance speed and accuracy based on their needs. High is the best setting for coding and logic, according to OpenAI, while low equals "fast at advanced reasoning."
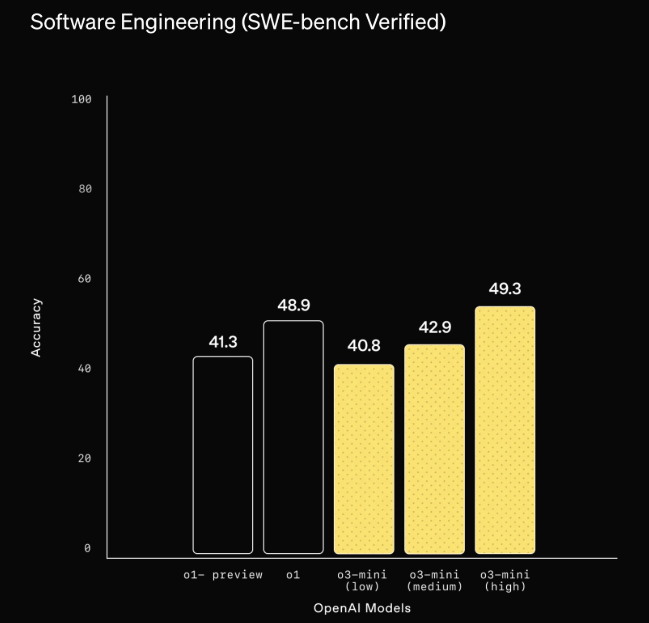
The free o3-mini version in ChatGPT is set to "medium" to "provide a balanced trade-off between speed and accuracy." Only paying users can pick the high version.
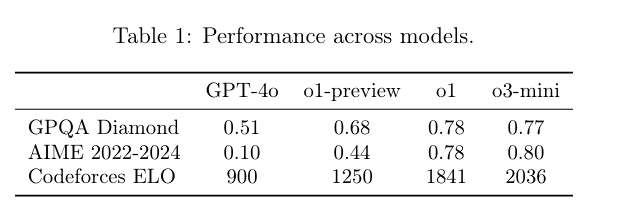
Depending on the level of reasoning chosen, it sometimes outperforms larger models such as o1-preview and o1, especially on coding tasks. The new model also responds in 7.7 seconds compared to 10.16 seconds for the o1-mini - a 24% improvement.
OpenAI says the model's training data combines public sources with internally developed data. The company likely pre-trained on high-quality web and book data, similar to traditional LLMs, and generated synthetic training data specifically for STEM tasks that can be clearly classified as correct or incorrect for the reinforcement learning used in the o-series. Writing, text and creative tasks don't benefit from this training method, which is why OpenAI recommends the o-series primarily for logic tasks and analyses.
New features and pricing
Free ChatGPT users can access o3-mini through the "Reason" option in chat or when regenerating an answer. Plus and Team users now get 150 messages per day, up from 50, while Pro users have unlimited access. o3-mini Reasoning is also available in Microsoft Copilot as "Think Deeper", though Microsoft uses o1.
In addition, OpenAI has added a search function to o3-mini that provides current answers with links to web sources, calling it an early prototype that they plan to expand to all reasoning models.
For API users, prices are 93% lower than o1. Input tokens cost $1.10 per million, with cache tokens half that price. Output tokens cost $4.40 per million. This is likely a response to Deepseek's cheap API pricing for its R1 model, which is also open source. The model is available today for "select developers" in usage tiers 3 to 5. It does not support vision capabilities like o1.
The model also features significantly higher output limits: o3-mini can generate up to 100,000 tokens (with a 200,000 token input limit), while GPT-4o is limited to 16,000 tokens. Competing models like R1 and Claude 3.5 only reach 8,000 tokens.
Safety considerations
According to the system card, o3-mini carries "medium risk" ratings in three areas: persuasiveness, CBRN risks (chemical, biological, radiological, nuclear), and model autonomy - similar to its predecessor.
The model's persuasiveness poses a notable concern. In tests, it convinced simulated victims to donate money 79% of the time and secured the highest donation amounts. It performs between the 80th and 90th percentile of human persuasiveness levels.
Sam Altman, CEO of OpenAI, has previously identified "superhuman" manipulation skills of AI as a risk factor, though according to OpenAI, this would only occur beyond the 95th percentile. o3-mini's capabilities match those of other OpenAI o-models and GPT-4o in this regard.
On fairness measures, o3-mini matches its predecessor with some variations. It achieves 82% accuracy on ambiguous questions and 96% on clear ones. The model shows less explicit discrimination in medical decision-making tests while maintaining average implicit bias levels. The model's 3.6% jailbreak success rate reflects its new "Deliberative Alignment" safety approach.

While o3-mini can perform complex software tasks autonomously, achieving 61% success in the SWE-bench Verified benchmark when using tools, it has a surprising weakness. In tests simulating real pull requests from OpenAI engineers, it failed completely with a 0% "success" rate.

According to OpenAI, this failure is primarily due to the model's inability to follow instructions correctly - instead of using the provided Python tools, o3-mini repeatedly tried to use non-existent bash commands, even after multiple corrections. These attempts resulted in long, fruitless conversations. It also shows that fully autonomous "agentic AI" may be a long way off, as reliability is its biggest problem.
OpenAI emphasizes that these test results may only represent the lower limit of actual capabilities. With improved testing methods and support, the model's performance could be significantly higher.
Correction: A previous version of this article stated that o3-mini is available in Copilot. Microsoft's reasoning function uses o1.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.