Paella is a compact and performant text to image AI model

An international team of researchers presents Paella, a text-to-image AI model optimized for performance.
Currently, the best-known text-to-image AI systems, like Stable Diffusion and DALL-E 2, are based on diffusion models for image generation and transformers for speech understanding. This enables high-quality image generation for text input.
However, the systems require multiple inference steps - and thus strong hardware - for good results. According to the Paella research team, this can complicate application scenarios for end users.
Back to GANs
The team introduces Paella, a text-to-image model with 573 million parameters. According to the researchers, it uses a performance-optimized f8-VQGAN architecture (convolutional neural network, see explanatory video at the end of the article) with a medium compression ratio and CLIP embeddings.
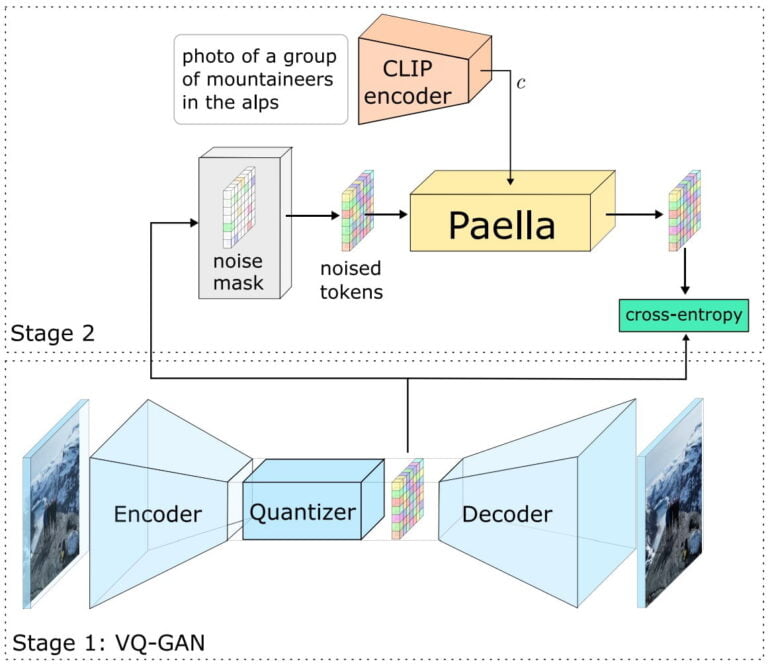
GA networks became widespread as deepfakes gained popularity before recently being eclipsed by diffusion methods. However, the research team sees the Paella architecture as a high-performance alternative to Diffusion and Transformer: Paella can generate a 256 x 256 pixel image in just eight steps and in less than 500 milliseconds on an Nvidia A100 GPU. Paella was trained for two weeks with 600 million images from the LAION-5B aesthetics dataset on 64 Nvidia A100 GPUs.

With our model, we can sample images with as few as 8 steps while still achieving high-fidelity results, making the model attractive for use-cases that are limited by requirements on latency, memory or computational complexity.
From the paper
In addition to image generation, Paella can modify the input images with techniques such as inpainting (changing the content of the image based on the text), outpainting (expanding the subject based on the text), and structural editing. Paella also supports prompt variations such as specific painting styles (e.g. watercolor).

The research team particularly highlights the small amount of code - just 400 lines - used to train and run Paella. This simplicity compared to transformer and diffusion models could make generative AI techniques manageable for more people, including those outside of research, they say.
The team makes its code and model available on Github. A demo of Paella is available at Huggingface. Image generation is fast and matches the text, but image quality cannot yet match diffusion models.
However, the researchers point to the comparatively small number of images used for training, which makes it difficult to make a fair comparison with other models, "especially when many of these models are kept private."
In this sense, the authors see Paella, along with the publication of the model and code, as contributing to "reproducible and transparent science." The lead author of the Paella study is Dominic Rampas of the Ingolstadt University of Technology.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.