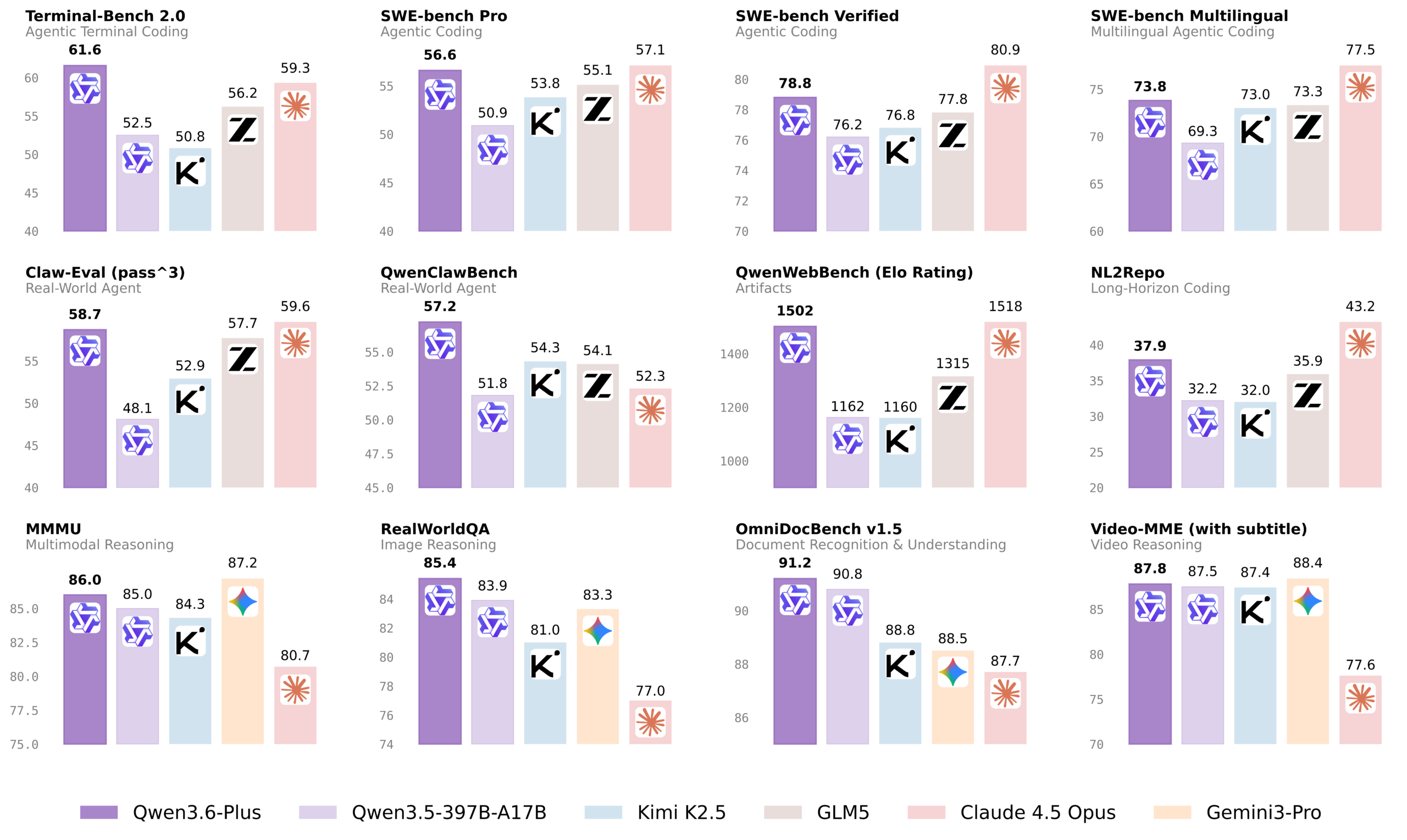
Alibaba has released Qwen3.6-Plus, its third proprietary AI model in just a few days. The model is available through the Alibaba Cloud Model Studio API and offers a context window of one million tokens. According to the Qwen team, the focus is on significantly improved capabilities for agentic coding, including frontend development and complex code tasks.
In benchmarks published by Alibaba, the model partially outperforms Anthropic's older flagship model Claude 4.5 Opus, which was replaced by the stronger 4.6 Opus in December 2025. It's worth noting that some of these measurements were conducted by Alibaba itself.
Qwen3.6-Plus outperforms the older 3.5 model and in some cases beats Opus. However, the Opus 4.6 released in December 2025 scores 65.4 percent on Terminal-Bench 2.0, putting it ahead of Qwen3.6-Plus. | Image: Alibaba
For a long time, Alibaba released its Qwen models as open source, but the company has recently changed course. The latest Qwen3.5-Omni is also not freely available. Alibaba wants to drive more revenue from enterprise customers with its proprietary models, as its cloud division faces intense competition from ByteDance.
According to Bloomberg, Alibaba is targeting $100 billion in AI revenue over the next five years. Qwen3.6-Plus will be integrated into the Qwen chatbot app and the company's new enterprise AI service Wukong.
Chinese chipmakers captured nearly 41 percent of China's AI accelerator server market in 2025, according to an IDC report seen by Reuters. IDC is a global market research firm specializing in the technology industry.
Nvidia remains the market leader with roughly 2.2 million cards shipped and a 55 percent market share, but the company is losing ground fast. In total, about 4 million AI accelerator cards were shipped in China, according to the report.
Chinese vendors shipped a combined 1.65 million cards. Huawei leads the domestic pack with about 812,000 chips, followed by Alibaba's chip unit T-Head at 265,000 cards. Baidu Kunlunxin and Cambricon are tied at 116,000 units each. AMD held just 4 percent of the market.
Following the accidental leak of its AI coding tool's source code, Anthropic has had more than "8,000 copies and adaptations of the raw Claude Code instructions" removed from GitHub via a copyright request, the Wall Street Journal reports. One programmer already used AI tools to rewrite the code in different languages, keeping it available despite takedowns. This shows just how damaging a code leak is in the age of AI: once it's out, it spreads faster than anyone can contain it.
The code contains valuable techniques Anthropic uses to control its AI models as coding agents—the "harness"—including a "dreaming" function for task consolidation. Competitors now have a blueprint to replicate Claude Code's capabilities, weakening Anthropic's edge in an already cutthroat market.
Google Deepmind study exposes six "traps" that can easily hijack autonomous AI agents in the wild
AI agents are expected to browse the web on their own, handle emails, and carry out transactions. But the very environment they operate in can be weaponized against them. Researchers at Google Deepmind have put together the first systematic catalog of how websites, documents, and APIs can be used to manipulate, deceive, and hijack autonomous agents, and they’ve identified six main categories of attack.
EU bars AI-generated content from official communications, according to Politico
Politico reports that the Commission, Parliament, and Council have barred their press teams from using fully AI-generated content. Experts see a missed opportunity.
Perplexity AI is facing a class-action lawsuit. The company is accused of sharing personal user data from chats with Meta and Google, Bloomberg reports. The lawsuit was filed Tuesday in federal court in San Francisco.
According to the complaint, trackers are downloaded onto users' devices as soon as they log into Perplexity's home page. That is not unusual for many websites. What makes the allegation serious is the further claim: the trackers allegedly give Meta and Google access to conversations with the AI search engine. According to the lawsuit, this also applies when users enable "Incognito" mode.
The suit was filed on behalf of a man from Utah who says he shared financial and tax information with the chatbot. If certified, additional plaintiffs may join. Meta pointed to its policies, which prohibit advertisers from submitting sensitive data. Perplexity spokesperson Jesse Dwyer said the company has not been served with any such lawsuit. Google did not immediately comment.
OpenAI has officially closed its latest funding round. The company raised $122 billion at a valuation of $852 billion. Key backers include Amazon, Nvidia, SoftBank, and Microsoft, along with a16z, BlackRock, Sequoia Capital, and several other investors. Private investors put in $3 billion through banking channels, and the company also expanded its credit line to $4.7 billion.
OpenAI says it's now pulling in $2 billion in monthly revenue and has crossed 900 million weekly active ChatGPT users. The company also officially unveiled the ChatGPT Super App, a single product that rolls together ChatGPT, the Codex coding agent, web search, and what OpenAI describes as "our broader agentic capabilities into one agent-first experience."
The bulk of the new capital will go toward computing infrastructure. OpenAI is clearly leaning harder into enterprise going forward; the company recently killed off its Sora video model to free up compute and because it wasn't gaining traction anyway. Enterprise already accounts for more than 40 percent of the company's total revenue. "Our consumer scale becomes the front door for enterprise usage, as familiarity in daily life drives adoption at work," OpenAI writes.