Reformulating web documents into synthetic data addresses the growing limits of AI training data

Datology AI has introduced BeyondWeb, a new framework that uses synthetic data to train language models. The approach is designed to address the growing shortage of high-quality training data and claims to be far more efficient than previous methods.
While training budgets for large language models now reach trillions of tokens, good web data is getting harder to find. Datology AI sees this "wall of data" as a central challenge and positions BeyondWeb as a solution. The framework restructures existing web documents to be more information-dense, improves the educational tone, and reorganizes content for better training.
Performance gains
According to Datology AI, BeyondWeb boosts accuracy by 5.1 percentage points on 8B parameter models compared to Hugging Face's Cosmopedia and by 2.6 percentage points over Nvidia's Nemotron-CC dataset.
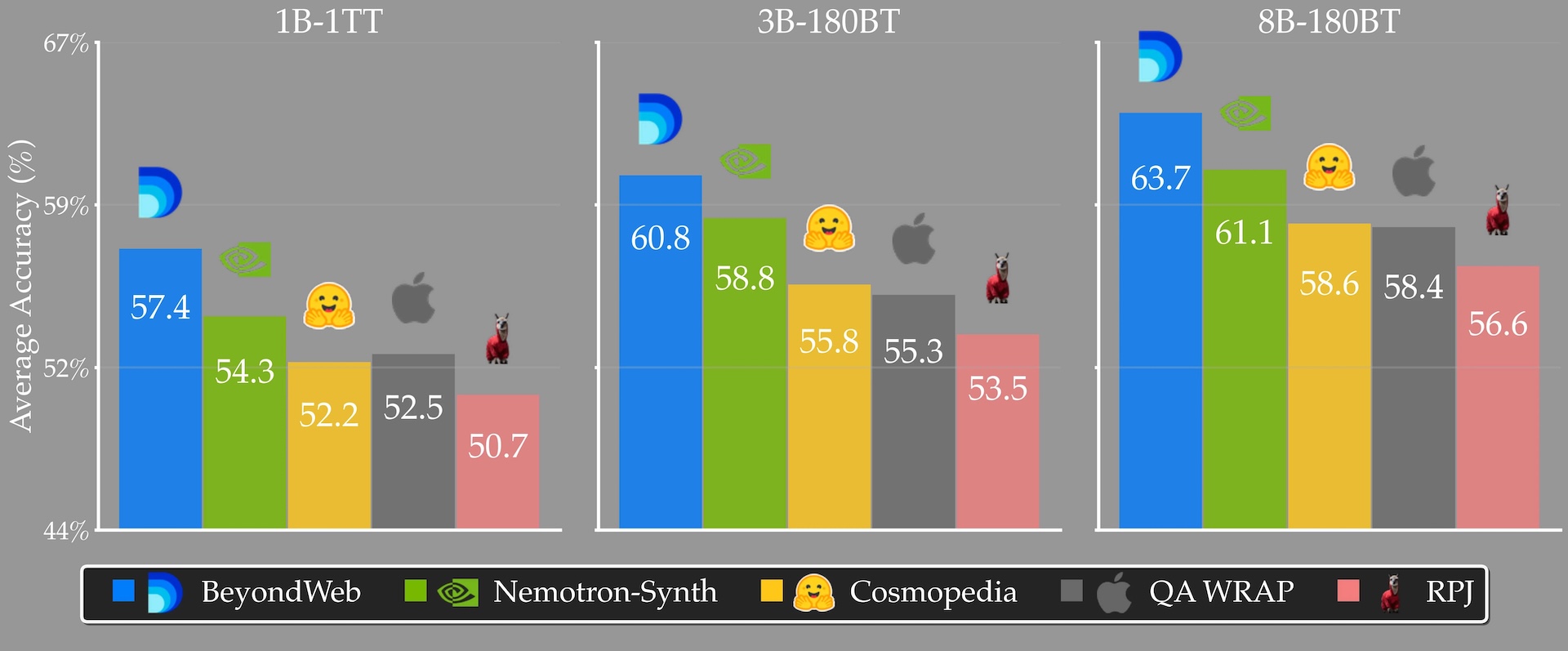
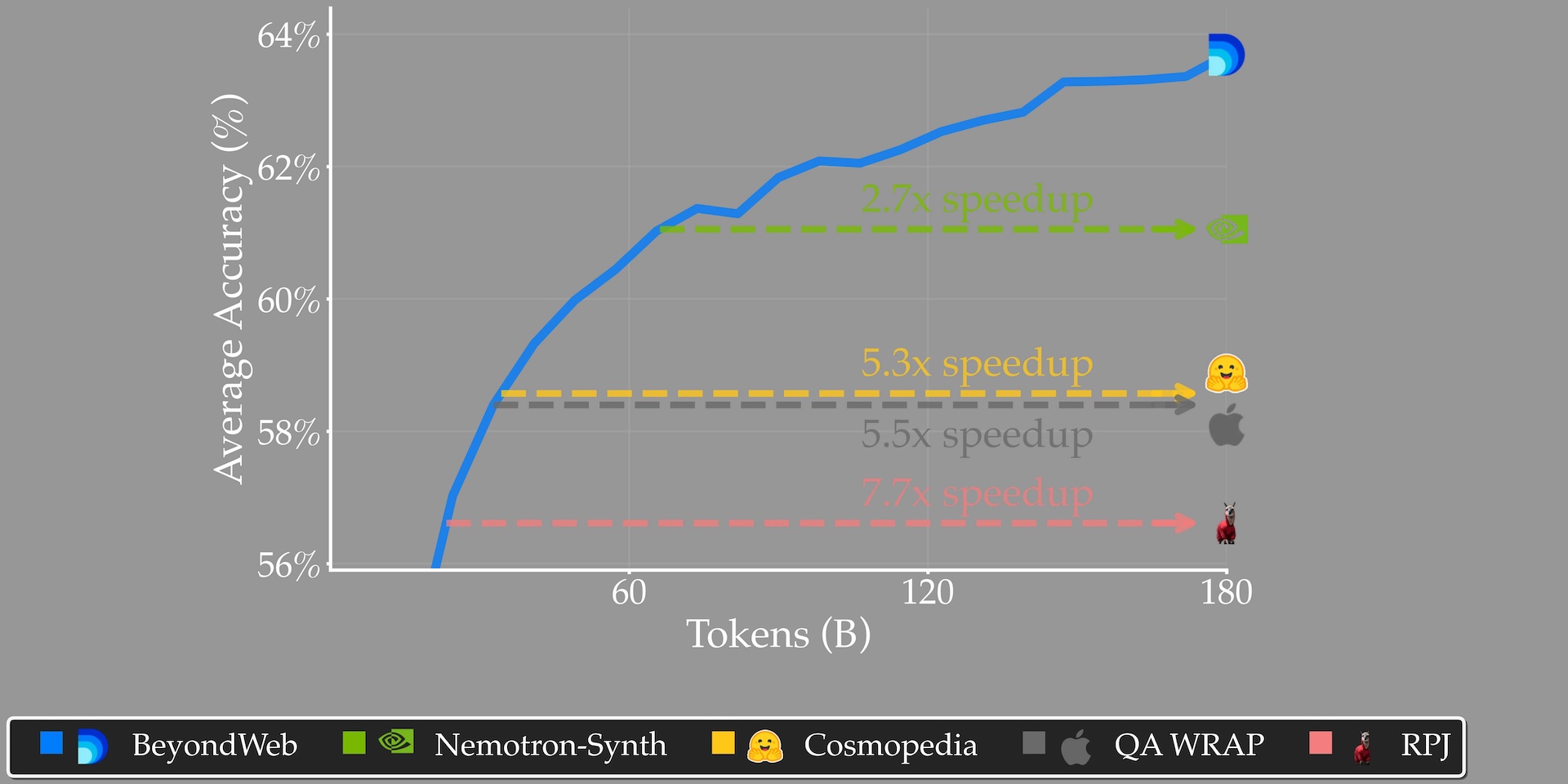
The study also found that BeyondWeb trains much faster: 7.7 times quicker than open web data and 2.7 times faster than Nemotron Synthetic. In one test, a 3B parameter model trained on BeyondWeb outperformed an 8B model trained on Cosmopedia using the same token budget.
The researchers looked at seven core questions around synthetic data generation. One key takeaway: diversity is essential for sustained progress. Standard methods may help early in training, but their lack of stylistic variety leads to diminishing returns.
Another finding: conversational style is underrepresented in web data, making up less than 2.7 percent, even though chat is the main use case for LLMs. Adding more conversational data helps, but gains plateau quickly.
Small models can be strong at reformulating text
Testing different model sizes, the team found that small language models can be effective at generating high-quality synthetic data. Moving from 1B to 3B parameters increased data quality by 1.5 percentage points, but improvements flattened out at 8B. This suggests that organizations with fewer resources can still generate strong synthetic datasets.
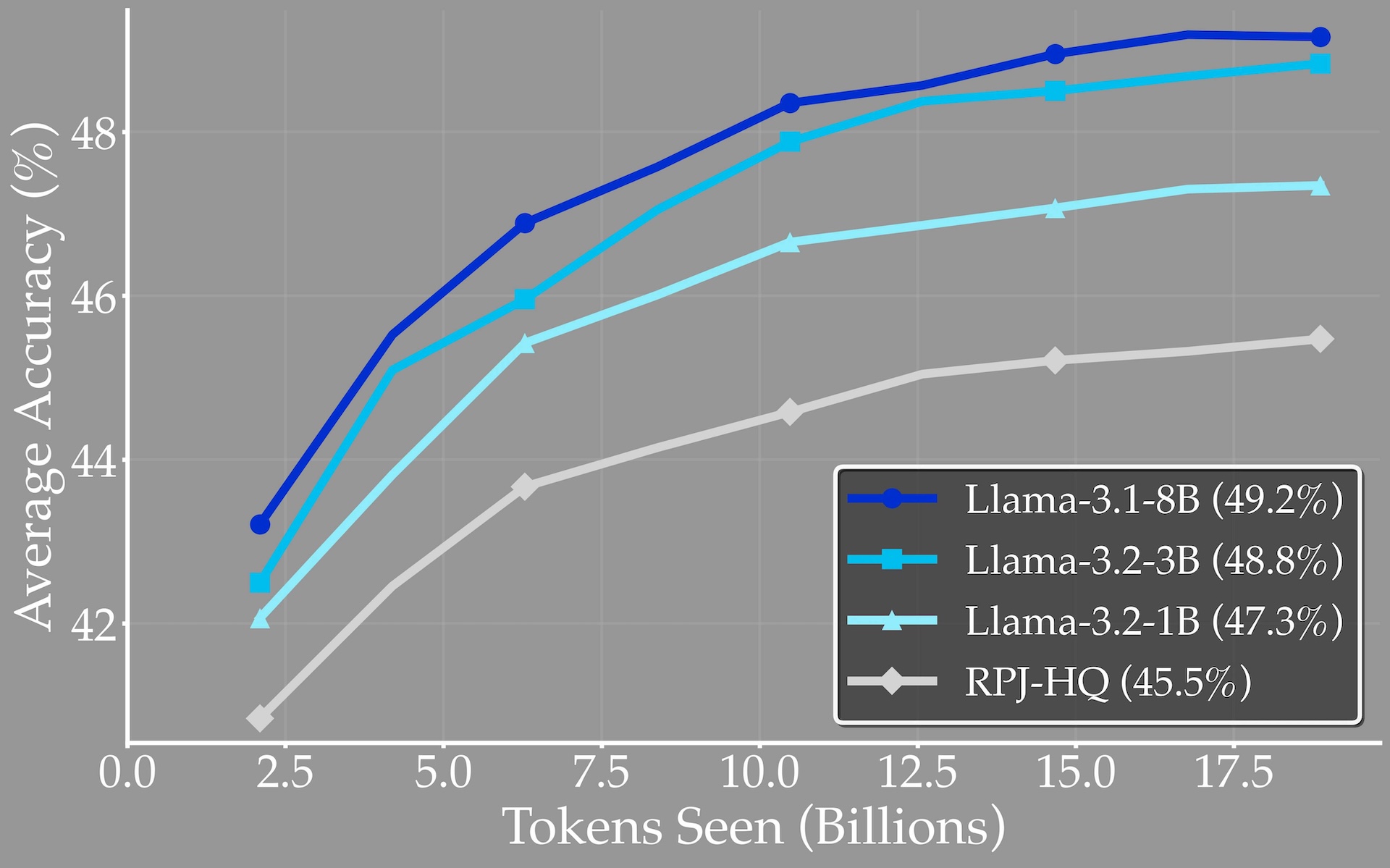
The researchers also tested different families of reformulator models and found that all produced similarly strong synthetic data. In other words, a model's overall benchmark score doesn't predict how good its synthetic data will be.
Real-world use
BeyondWeb has already been used to train ArceeAI's 4.5B parameter AFM model. For this, Datology AI built a scalable pipeline that can handle trillions of tokens. The team notes that generating top-quality synthetic data is complex, with many variables to fine-tune. BeyondWeb is not currently available for free research use.
Microsoft demonstrated the potential of synthetic data with Phi-4 in December 2024, training the model on 400 billion tokens of synthetic "textbook-style" data and introducing specialized "pivotal tokens" to improve learning. Phi-4 models deliver strong benchmark results, though they have received mixed reactions in real-world use.
Six months earlier, Nvidia released Nemotron-4 340B, a full open-source pipeline for generating synthetic data, with 98 percent of the Instruct model's training data created synthetically. Around the same time, researchers debunked the popular "model collapse" theory, showing that synthetic data can push AI development forward when used properly.
OpenAI also revealed during the GPT-5 announcement that the model was trained with synthetic data, likely produced by its in-house o3 model. While many companies use synthetic data primarily to cut costs, OpenAI said it focuses on carefully preparing data to enable real learning, not just to fill in gaps. Sébastien Bubeck, who previously led the Phi project at Microsoft, explained this approach.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.