Reka Core is the next multimodal AI model that makes GPT-4 seem less special
AI start-up Reka has introduced a new multimodal language model called Reka Core, which can compete with GPT-4 and understands video and audio in addition to text and images.
Reka claims that Reka Core is its most powerful model to date. It was developed from scratch in just a few months and was primarily trained on NVIDIA H100 GPUs with a peak performance of around 2,500 H100 and 2,500 A100 GPUs.
Unlike OpenAI's GPT-4, which can only process images in addition to text, Reka Core can understand text, images, videos, and audio files. This makes it similar to Google's recently released Gemini 1.5 Pro.
Video: Reka Core demo
Benchmarks show performance on par with leading models
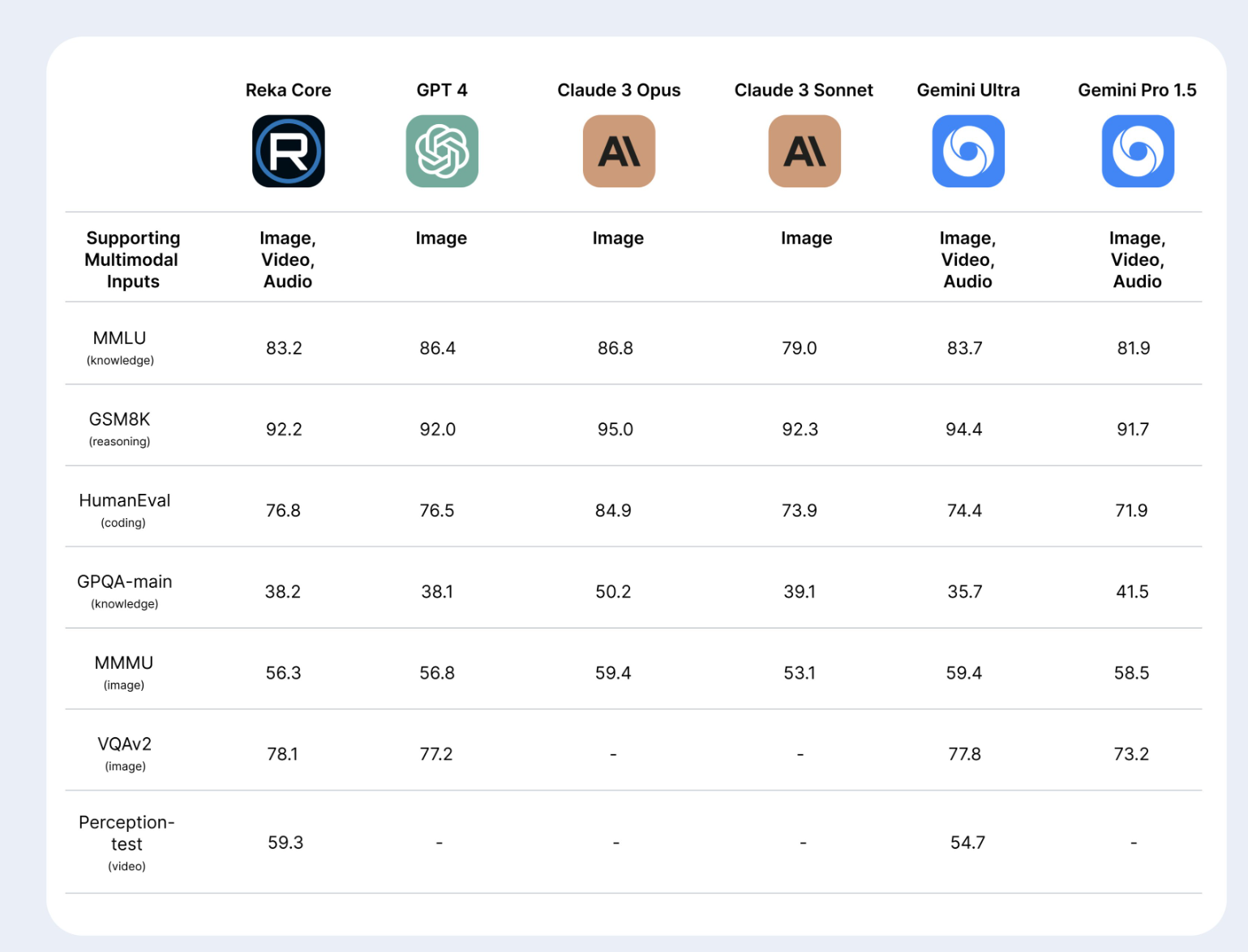
In initial benchmarks, Reka Core can keep up with leading models such as GPT-4, Anthropic's Claude 3, and Google's Gemini Ultra. In image understanding tasks like MMMU, Reka Core's performance of 56.3 percent is almost on par with GPT-4V (56.8 percent). Reka Core also outperformed Gemini Ultra (54.7 percent) in video analysis (perception test) with 59.3 percent.
In the MMLU benchmark for general language understanding and question-answering tasks, Reka Core achieved an accuracy of 83.2 percent. This puts it slightly behind GPT-4 (86.4 percent) but ahead of models like Claude 3 Sonnet (79 percent). In the GSM8K reasoning benchmark, Reka Core achieves 92.2 percent, which is on par with GPT-4 (92 percent).
In a blinded evaluation by an independent third-party company, Reka Core ranked second in multimodal chat, just behind GPT-4V and ahead of all Claude 3 models. In text-only chat, Reka Core placed third behind GPT-4 Turbo and Claude 3 Opus. Reka Core is still in the training phase, and the startup expects further improvements.
In addition to the flagship model Reka Core, the startup also introduced the smaller models Reka Flash and Reka Edge. With 21 billion parameters, Reka Flash outperforms many much larger models such as GPT-3.5, Gemini Pro 1.0, or Mistral in benchmarks like MMLU, HumanEval, or image understanding tasks despite its smaller size. In the MMLU benchmark, Flash achieves an accuracy of 75.9 percent, putting it ahead of Gemini Pro 1.0 (71.8 percent) and close to GPT-4 (86.4 percent).

The even more compact Reka Edge with 7 billion parameters outperforms Mistral-7B, Gemma-7B, and Llama-7B in benchmarks such as MMLU, GSM8K, or HumanEval. Edge achieves an accuracy of 65.7 percent in the MMLU compared to 64.3 percent for Gemma-7B and 62.5 percent for Mistral-7B.
According to Reka, Flash and Edge demonstrate that efficient training and model architectures can achieve top performance even with significantly fewer parameters. This makes them alternatives for applications where model size and inference costs are critical factors, for example, on mobile devices.
Technically, Reka Core is based on a modular encoder-decoder-transformer architecture. The model was pre-trained in several phases with different data mixtures, context lengths, and targets.
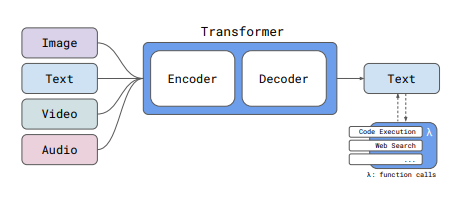
Reka Core has a context window of 128,000 tokens for long documents. The training covers a total of 32 languages. Reka Core's training data is a mixture of publicly available and licensed, proprietary datasets with a state of knowledge up to November 2023. In total, approximately 5 trillion deduplicated text tokens were used.
About 25 percent of the data is code, 30 percent STEM, and 25 percent web data. Multilingual data makes up 15 percent, covering 32 prioritized languages. Additionally, the entire Wikipedia corpus with 110 languages is part of the training dataset. Large multimodal datasets were used for images, video, and audio, which were optimized in terms of quality, diversity, and scope.
Showcase and API available
You can view sample outputs of Reka Core in a public showcase. The model can also be used via a web platform, API, locally or on end devices. Initial partners include Snowflake, Oracle and AI Singapore.
In terms of price, Reka's most expensive Core model is well behind Claude 3 Opus and roughly on a par with GPT-4 Turbo.
Reka Core:
- $10 / 1M input token
- $25 / 1M output token
Claude 3 Opus (from Anthropic):
- $15 / 1M input tokens
- $75 / 1M output token
GPT-4 Turbo (from OpenAI):
- $10 / 1M input token
- $30 / 1M output token (for the 128K model)
Reka is an AI startup focused on universal intelligence, universal multimodal and multilingual agents, self-improving AI, and model efficiency. The startup was founded by researchers from DeepMind, Google, Baidu, and Meta and made its first public appearance in June 2023.
Most recently, Reka developed Yasa-1, a multimodal AI assistant that can understand and interact with text, images, video, and audio. Reka is headquartered in San Francisco and has an office in the UK.
Personalization trumps foundation models
Reka Core also shows that GPT-4 in April 2024 is no longer the overwhelming AI model it seemed to be a few months ago. In addition to Reka Core, Gemini 1.5, and Claude 3, numerous models from smaller companies have at least caught up. Llama 3 is in the starting blocks.
The technological gap in building AI models seems to be closing. With the stealth acquisition of Inflection AI by Microsoft, the first startup has recently fallen victim to this development - despite about $1.5 billion in funding. How many large AI models with similar capabilities does the world need?
In a recent podcast, OpenAI CEO Sam Altman said that he believes foundational AI models will be less important in the future; instead, everything will revolve around personalization.
OpenAI and Google are reportedly focusing their research on LLM-driven personalized AI agents that can automate entire work processes. OpenAI has also expanded its offerings to customize AI models for businesses.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.