Version 2.0 of Stable Diffusion brings numerous advancements. The most important new feature is the improved text-to-image model OpenCLIP.
In August 2022, AI startup Stability AI, together with RunwayML, LMU Munich, EleutherAI and LAION, released Stable Diffusion, an open-source image AI that was immediately well received by the community.
Stable Diffusion can be used online for a fee and with content filters, or downloaded for free and used locally without content restrictions. Version 2.0 continues this open source approach. Leading the way is Stability AI.
Improved text encoder and new image modes
For version 2.0, the team used OpenCLIP (Contrastive Language-Image Pre-training), an improved version of the multimodal AI system that learns visual concepts from natural language self-supervised. OpenCLIP was released by LAION in three versions in mid-September and is now implemented in Stable Diffusion. Stability AI supported the training of OpenCLIP. CLIP models can compute representations of images and text as embeddings and compare their similarity. In this way, an AI system can generate an image that matches a text.
Thanks to this new text encoder, Stable Diffusion 2.0 can generate significantly better images compared to version 1.0, according to Stability AI. The model can generate images with resolutions of 512x512 and 769x768 pixels, which are then upscaled to 2048x2048 pixels by an upscaler diffusion model that is also new.

The new Open CLIP model was trained with an "aesthetic dataset" compiled by Stability AI based on the LAION-5B dataset. Sexual and pornographic content was filtered beforehand.
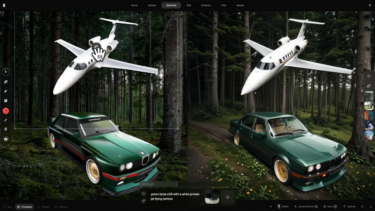
Also new is a depth-to-image model that analyzes the depth of an input image and then uses text input to transform it into new motifs with the contours of the original image.

Stable Diffusion version 2.0 also gets an inpainting model that can be used to replace individual image elements within an existing image, such as painting a cap or VR headset on the head.
Inpainting
Finally, we also include a new text-guided inpainting model, fine-tuned on the new Stable Diffusion 2.0 base text-to-image model, which makes it super easy to switch out parts of an image intelligently and quickly. pic.twitter.com/3fKng0ti3S
- Stability AI (@StabilityAI) November 24, 2022

Open source as a model for success
Despite the numerous improvements, Stable Diffusion version 2.0 should still run locally on a single powerful graphics card with sufficient memory.
We’ve already seen that, when millions of people get their hands on these models, they collectively create some truly amazing things. This is the power of open source: tapping the vast potential of millions of talented people who might not have the resources to train a state-of-the-art model, but who have the ability to do something incredible with one.
Stability AI
More information and access to the new models are available on Github. They should also be available for the Stable Diffusion web interface Dreamstudio in the coming days. Developers can find more information in the Stability AI API documentation.