Users share initial reactions to OpenAI's new "o1" AI model

OpenAI's latest AI model, nicknamed "Strawberry," has generated plenty of buzz in the AI bubble since it's release yesterday.
The model, officially called o1-preview and o1-mini, launched to high expectations as leaks have been building hype for months. Experts are now weighing in with their first impressions, and the reactions are mixed, with some impressed and others skeptical.
The main selling point of the o1 model is its ability to "think" before it answers. OpenAI claims that this leads to better results, but not everyone is convinced.
Gary Marcus is initially impressed
Gary Marcus admits the model is "impressive." However, he's not ready to call it a breakthrough in general AI.
Marcus points out two main issues with the model. First, there's a lack of detailed information about how the model works. Second, there's incomplete disclosure of benchmark results.
Marcus is also skeptical about OpenAI's claim that longer thinking time leads to better results. He argues that there's no solid evidence for this claim yet.
The argument that it does cool things in a few seconds, therefore it will be amazing if you give it a month to run is HIGHLY speculative, and probably won't work nearly as well as OpenAI wants you to think. (I don't yet even see any data that running the system for a week makes a massive difference relative to running it a minute.)
Gary Marcus on X
Currently, only a preview version of o1 is available to paying subscribers. The full model shown in benchmarks isn't accessible to the public or researchers. This limitation restricts the scientific community's ability to verify OpenAI's claims about the model's capabilities.
"Amazing, but still limited"
Scientist Ethan Mollick, who's had early access to o1, calls it "amazing, still limited, and, perhaps most importantly, a signal of where things are heading."
Mollick notes that o1 excels at complex problems requiring planning. However, he points out that it doesn't outperform its predecessor in all areas. For example, it's not better at writing tasks.
To demonstrate o1's abilities, Mollick tested it with a complex crossword puzzle. The model initially struggled but managed to solve it after receiving a key hint.
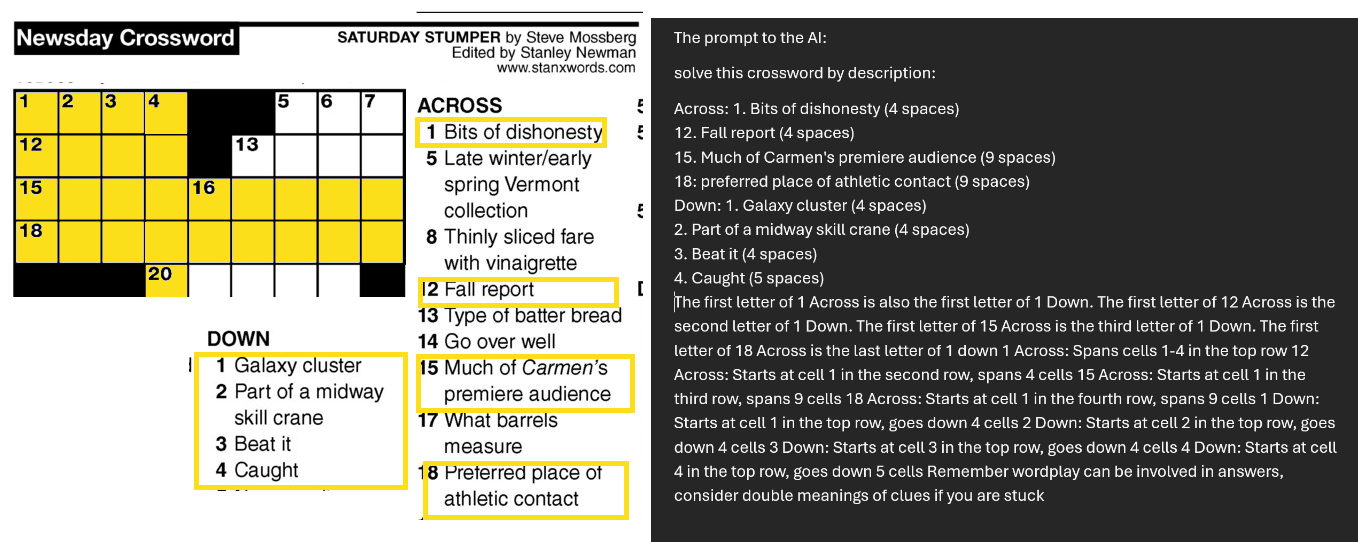
Mollick says that while the model's planning abilities show a form of agency, errors and hallucinations still occur, and it remains constrained by GPT-4o's underlying intelligence.
Will prompts become (even) more important?
Former OpenAI contributor and early access user Andrew Mayne offers tips for effectively prompting o1. He advises users to treat the model like a smart friend and to provide detailed, well-thought-out prompts. Mayne also recommends using o1-mini for tasks that need step-by-step thinking.
OpenAI recommends keeping prompts simple and direct. They advise against over-guiding the model or providing too much additional context, especially in RAG scenarios, as this can complicate the model's responses. Additional chain-of-thought instructions should be avoided, as the models are already inferring logically internally.
For clarity, OpenAI suggests using delimiters such as triple quotes, XML tags, and headings. When using Retrieval Augmented Generation (RAG) models, OpenAI advises against adding too much extra context, as this can complicate the models' responses.
Developer Simon Willison raises an important issue about o1's "reasoning tokens." These tokens, which represent the model's thought process, aren't visible in API responses but still count as output tokens. Willison argues that this lack of transparency is a step backward for AI development. He stresses the importance of interpretability in language models.
I’m not at all happy about this policy decision. As someone who develops against LLMs interpretability and transparency are everything to me—the idea that I can run a complex prompt and have key details of how that prompt was evaluated hidden from me feels like a big step backwards.
Simon Willison
Early User Experiments
OpenAI quickly made the new model available to many ChatGPT users, leading to a flood of example interactions online. These examples showcase both the model's progress and its lingering shortcomings.
One notable weakness of ChatGPT, even with the updated GPT-4o, has been its struggle with simple letter-counting tasks. The now-famous test of counting the "R"s in "Strawberry" consistently tripped up GPT-4o.
O1-preview seems to have solved this particular problem, reliably counting letters when asked. However, it still stumbles on other basic tasks.
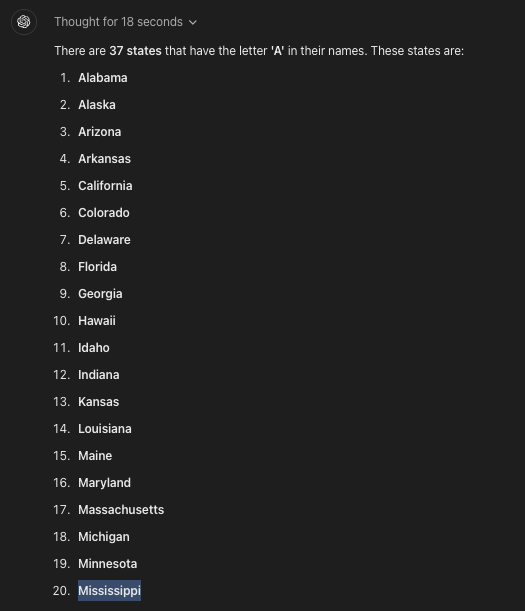
Ed Zitron reported that when asked to list all US states containing the letter "a", o1-preview failed – oddly including "Mississippi" as the 20th entry. This error occurred despite the model reportedly taking 18 seconds to "think" before answering.
One notable success for o1 came in the realm of creative writing. Mehran Jalali challenged the model to write a poem with highly specific constraints, including particular rhyme schemes and word choices.
According to Jalali, o1 not only completed this complex task but did so with a level of skill that surpassed all other language models he had tested. This demonstration shows o1's potential for handling rule-based creative tasks.

Developer Ammaar Reshi paired the model with Cursor, an AI-powered code editor. Using this combination, Reshi was able to create a fully functional iOS weather app, complete with animations, in less than ten minutes.
Video: Ammaar Reshi/X
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.