VALL-E 2: Microsoft's new AI voice tech is so good they're afraid to release it

A research team at Microsoft has introduced VALL-E 2, a significantly improved AI system for speech synthesis. However, they believe the world is not ready for its release.
According to the team, it is the first system to achieve human-level performance in generating speech from text, even for unknown speakers with only a short speech sample available. It can reliably create complex sentences or those with many repetitions.
Commercially available software like ElevenLabs is able to clone voices, but requires more lengthy reference material. VALL-E 2 can do it with just a few seconds.
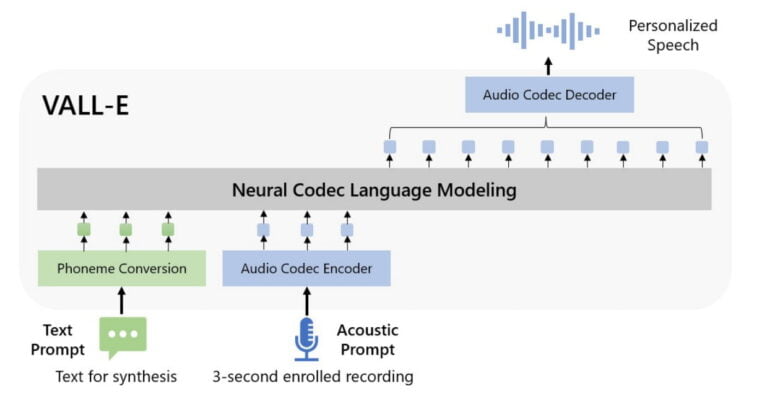
VALL-E 2 builds on its predecessor VALL-E from early 2023 and uses neural codec language models to generate speech. These models learn to represent speech as a sequence of codes, similar to digital audio compression. Two key improvements make the breakthrough possible.
VALL-E 2 delivers two central innovations
Firstly, VALL-E 2 employs a novel "Repetition Aware Sampling" method for the decoding process, where the learned codes are converted into audible speech. The selection of codes dynamically adapts to their repetition in the previous output sequence.
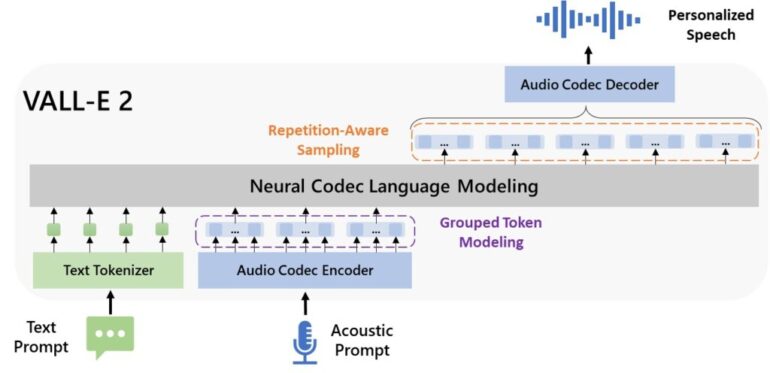
Instead of randomly selecting from possible codes like VALL-E, VALL-E 2 intelligently switches between two sampling methods: "Nucleus Sampling" only considers the most likely codes, while random sampling treats all possibilities equally. This adaptive switching significantly improves the stability of the decoding process and avoids issues like infinite loops.
The second central innovation is modeling the codec codes in groups instead of individually. VALL-E 2 combines multiple consecutive codes and processes them together as a kind of "frame". This code grouping shortens the input sequence for the language model, speeding up processing. At the same time, this approach also improves the quality of the generated speech by simplifying the processing of very long contexts.
A three-second sample as a voice reference.
Prompt: They moved thereafter cautiously about the hat groping before and about them to find something to show that Warrenton had fulfilled his mission.
In experiments on the LibriSpeech and VCTK datasets, VALL-E 2 significantly outperformed human performance in terms of robustness, naturalness, and similarity of the generated speech. Just 3-second recordings of the target speakers were sufficient. With longer 10-second speech samples, the system achieved audibly better results. Microsoft has published all examples on this website.
A three-second sample as a voice reference.
The synthesized voice with a 3-second sample.
The synthesized voice with a 10-second sample.
The researchers emphasize that training VALL-E 2 only requires pairs of speech recordings and their transcriptions without time codes.
No release due to high risk of misuse
According to the researchers, VALL-E 2 could be used in many areas such as education, entertainment, accessibility, or translation. However, they also point out obvious risks of misuse, such as imitating voices without the speaker's consent. Therefore, it currently remains a pure research project and Microsoft has no plans to integrate VALL-E 2 into a product or expand access to the public.
In their opinion, a protocol should first be developed to ensure that the person being heard has consented to the synthesis, as well as a method for digitally marking such content. This proposal is presumably inspired by developments in the AI image model industry, where watermarks like C2PA are being introduced. However, they do not solve the existing problem of reliably recognizing AI-generated content as such.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.