Video-ChatGPT analyzes videos and explains why they might be funny

Video-ChatGPT can describe video over time, solving textual tasks such as describing safety risks in a scene, highlighting humorous aspects, or generating matching ad copy.
While companies like Runway ML are making strides in converting text to video, Video-ChatGPT goes the other way, giving a language model the ability to analyze video. Video-ChatGPT can describe the content of a video in text, for example, explaining why a clip might be funny by highlighting an unusual element.
The developers demonstrate this with a video of a giraffe jumping into the water from a diving board. "This is not a common sight, as giraffes are not known for their acrobatics skills or diving abilites," Video-ChatGPT points out.
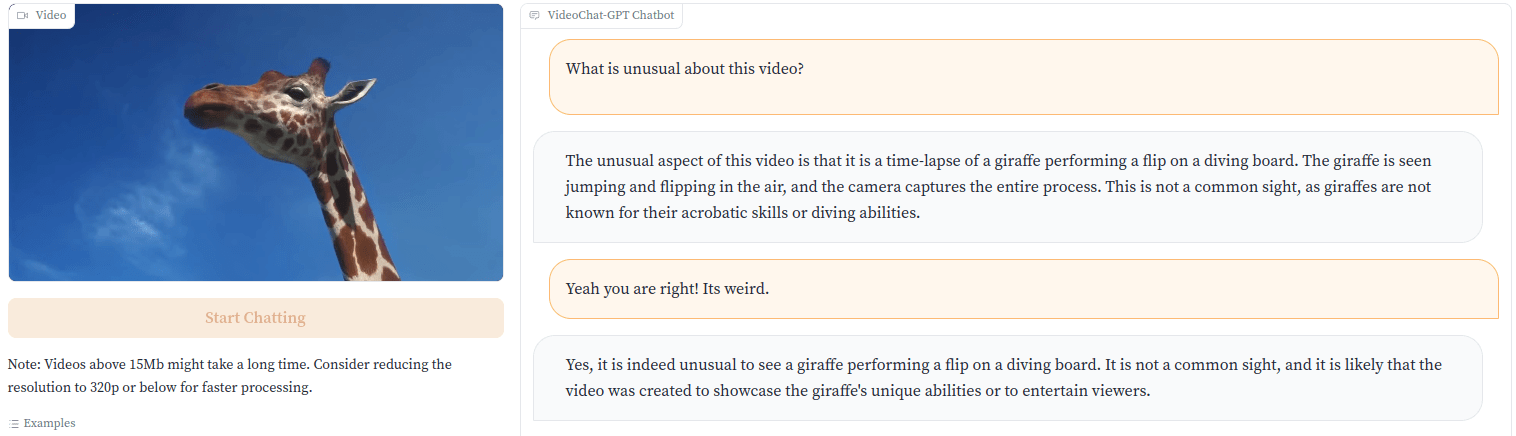
Image: Maaz et al.
Pre-trained video encoder linked to an open-source language model
The researchers describe the design of Video-ChatGPT as simple and easily scalable. It uses a pre-trained video encoder and combines it with a pre-trained and then fine-tuned language model.
Despite its name, the project from the Mohamed bin Zayed University of Artificial Intelligence in Abu Dhabi does not use OpenAI technology. Instead, it builds on the open-source Vicuna-7B model. The researchers embedded a linear layer to connect the video encoder to the language model.
In addition to the user prompt that asks for a specific task, the language model is also prompted with a system command that defines its role and general job.

Human and machine-enhanced dataset
The researchers used a mix of human annotation and semi-automated methods to generate high-quality data to fine-tune the Vicuna model. This data ranges from detailed descriptions to creative tasks and interviews and covers a variety of different concepts.
In total, the dataset contains approximately 86,000 high-quality question-answer pairs, some annotated by humans, some annotated by GPT models, and some annotated with context from image analysis systems.

The heart of Video-ChatGPT is its ability to combine video understanding and text generation. It has been extensively tested for its capabilities in video reasoning, creativity, and understanding of time and space. See more examples in the video below and in the GitHub repository.
For now, Video-ChatGPT is only available as an online demo, but the developers plan to release code and models on GitHub in the near future.
Multimodal AI future
After recent significant advances in text generation, companies like OpenAI and Google are turning to multimodal models. Bard understands and can respond to images, and GPT-4 demonstrated these capabilities at its official launch, although OpenAI has not yet released it.
Going from images to moving images would be the next logical step. Google has already announced the development of a large multimodal AI model with Project Gemini, to be released later this year.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- More than 16% discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.