Anthropic researchers teach language models to fine-tune themselves

Researchers working with AI company Anthropic have developed a new method called Internal Coherence Maximization (ICM) that fine-tunes language models using only their own outputs. The approach could help—or even replace—human oversight for complex tasks.
Traditionally, large language models are fine-tuned using human supervision, such as example answers or feedback. But as models grow larger and their tasks more complicated, human oversight becomes less reliable, argue researchers from Anthropic, Schmidt Sciences, Independet, Constellation, New York University, and George Washington University in a new study.
Their solution is an algorithm called Internal Coherence Maximization, or ICM, which trains models without external labels—relying solely on internal consistency.
The model evaluates itself—and learns from it
ICM is based on a simple idea: a language model like Claude or Llama should figure out for itself which answer to a question is correct, and it does so using two main criteria.
The first is mutual predictability. This means the model checks whether it can reliably infer the correct answer to a new question based on its answers to similar previous questions. If the model recognizes patterns from similar cases, it can apply them to new answers, creating an internal coherence—a set of answers that fit together and reflect a shared understanding.
The second is logical consistency. Here, the model checks its own responses for contradictions. For example, if the model labels two different solutions to the same math problem as "correct," even though the results differ, that's a logical conflict. ICM works to actively avoid these kinds of contradictions.
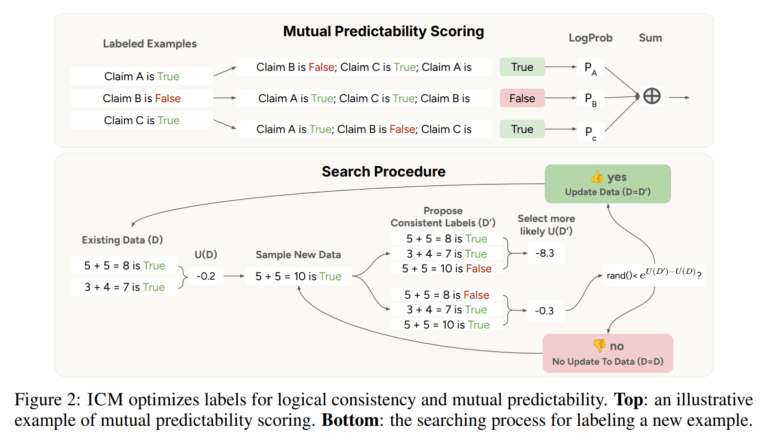
By combining these two principles, the model essentially cross-checks itself: it looks for a set of answers that are mutually consistent and from which each answer can be derived from the others. This lets the language model leverage its existing knowledge to make better decisions—entirely without external guidance.
The process starts with a small set of randomly labeled examples. From there, the model iteratively evaluates new answers, searches for contradictions, and adjusts its judgments as needed.
Outperforming human labels—on some tasks
In tests on three established benchmarks—TruthfulQA (truthfulness), GSM8K (math accuracy), and Alpaca (helpfulness)—ICM performed at least as well as traditional training with "gold" labels or human supervision.
On Alpaca, which uses especially subjective criteria like helpfulness and harmlessness, ICM even outperformed training with human-annotated data. According to the researchers, this suggests that language models already internalize these concepts—they just need the right way to activate them.
Another experiment tested whether a model could determine an author's gender from a text. While humans identified the correct gender 60% of the time, ICM achieved 80% accuracy. The model was not specifically trained to detect gender; it simply relied on its existing language knowledge.
A language assistant without human training
The team also used ICM to train a reward model—again, with no human labels. This reward model was then used for reinforcement learning to train the Claude 3.5 Haiku chatbot.
The ICM-trained chatbot won 60% of head-to-head comparisons with a version trained under human supervision. The study's authors say this is strong evidence that ICM can scale beyond research and work in production settings.
There are limits, though. ICM only works for concepts the model already knows. In a test where the model was supposed to learn a personal preference for poems mentioning "sun", ICM failed—performance was no better than random. The method also struggles with long inputs, since many examples need to fit inside the model's context window.
The researchers believe ICM could be a way to better align language models with human values—without inheriting human flaws like bias or inconsistency, especially for complex tasks where even people struggle to provide reliable labels. One of the paper's coauthors is security researcher Jan Leike, who recently left OpenAI's Superalignment team before its breakup and publicly criticized the company’s direction.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.