Apple introduces Manzano, a model for both image understanding and generation

Apple is working on Manzano, a new image model designed to handle both image understanding and image generation. This dual capability is a technical hurdle that has kept most open-source models a step behind commercial systems like those from OpenAI and Google, Apple says.
Manzano has not been released to the public, and there is no demo yet. Instead, Apple researchers have shared a research paper with low-resolution image samples for tough prompts. These examples are compared with outputs from open-source models like Deepseek Janus Pro and commercial systems such as GPT-4o and Gemini 2.5 Flash Image Generation, also known as "Nano Banana."

Apple points to a core limitation in most open-source models: they often have to choose between strong image analysis and strong image generation. Commercial systems tend to handle both. In their paper, Apple researchers say current models especially struggle with tasks that involve lots of text, like reading documents or interpreting diagrams.
According to Apple, the problem comes down to how models process images. Continuous data streams are better for understanding, while discrete tokens are needed for generating images. Most models use separate tools for these tasks, which can cause conflicts inside the language model.
Hybrid system design
Manzano, which means "apple tree" in Spanish, uses a hybrid image tokenizer as its core idea. This setup uses a shared image encoder that outputs two types of tokens. Continuous tokens represent images as floating point numbers for comprehension, and discrete tokens divide images into fixed categories for generation. Since both streams come from the same encoder, the usual conflicts between these two tasks are reduced.
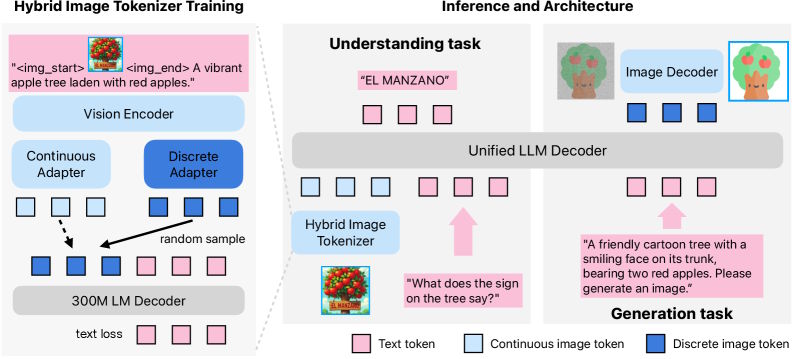
Manzano's architecture has three main parts: the hybrid tokenizer, a unified language model, and a separate image decoder for final output. Apple built three versions of the image decoder with 0.9 billion, 1.75 billion, and 3.52 billion parameters, supporting resolutions from 256 up to 2048 pixels.
Training happens in three stages, using 2.3 billion image-to-text pairs from public and internal sources, plus one billion internal text-to-image pairs. In total, the researchers use 1.6 trillion tokens. Some training data comes from synthetic sources like DALL-E 3 and ShareGPT-4o.
Benchmark results
In Apple's own tests, Manzano outperforms other models on benchmarks. On ScienceQA, MMMU, and MathVista, the 30 billion parameter version scores especially well on text-heavy tasks like diagram and document analysis. Scaling tests indicate that performance continues to improve as the model size grows from 300 million to 30 billion parameters. For example, the 3 billion parameter version scores over 10 points higher than the smallest model on several tasks.
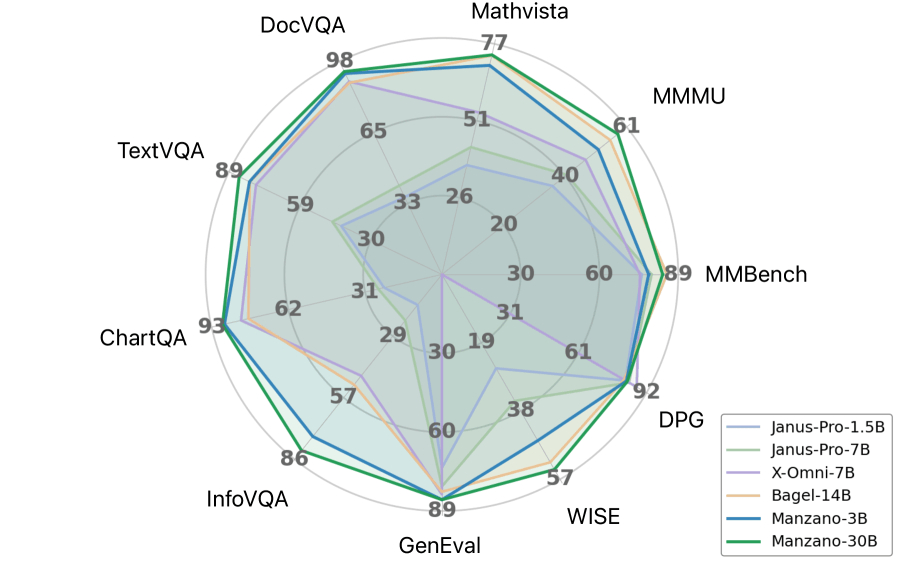
Apple also compared the unified model to specialized systems and found only minor performance differences. For the 3 billion parameter model, the gap was less than one point. On image generation benchmarks, Manzano again ranks near the top in Apple's tests. The system can follow complex instructions, transfer styles, add images, and estimate depth.

Apple sees Manzano as a credible alternative to current models and suggests its modular design could shape future multimodal AI. The separate components make it possible to update each part independently and use training methods from different areas of AI research.
Still, Apple's Foundation models lag behind the leaders, even with a new on-device AI framework. To help close the gap, Apple plans to use OpenAI's GPT-5 in Apple Intelligence starting with iOS 26. Manzano shows technical progress, but only future updates will reveal whether this approach can really reduce reliance on outside models.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.