Stable Video Diffusion: The best open source AI video model gets a major update

Update –
- Added info about SVD 1.1
Stability AI releases the first major update to Stable Video Diffusion, the company's generative video model.
Updated to Stable Video Diffusion (SVD) 1.1, the model is designed to produce AI-generated videos with better motion and consistency. Like its predecessor, it is publicly available and can be downloaded via Hugging Face. A Stability AI membership is required for commercial use.
The company launched a subscription service for commercial use of its models in December 2023; for non-commercial use, all models are still available as open source.
According to the model card, SVD 1.1 is a refined version of the previously released SVD-XT and generates four-second videos with 25 frames and a resolution of 1024 x 576 pixels.
Original article from November 21, 2023:
Stable Video Diffusion is released in the form of two image-to-video models, each capable of generating 14 and 25 images with customizable frame rates ranging from 3 to 30 frames per second.
Based on the Stable Diffusion image model, the Video Diffusion model was trained by Stability AI on a carefully curated dataset of specially curated, high-quality video data.
It went through three phases: text-to-image pre-training, video pre-training with a large dataset of low-resolution video, and finally video fine-tuning with a much smaller dataset of high-resolution video.

Stable Video Diffusion outperforms commercial models
According to Stability AI, at the time of release, Stable Video Diffusion outperformed leading commercial models such as RunwayML and Pika Labs in user preference studies. Stability AI showed human raters generated videos in a web interface and then had them rate the video quality in terms of visual quality and prompt following.
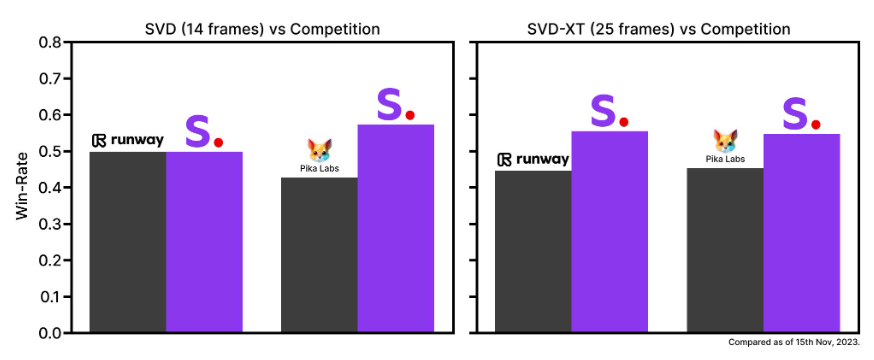
However, RunwayML and Pika Labs were recently outperformed by Meta's new video model, Emu Video, by an even larger margin. So Emu Video is probably still the best video model right now, but it is only available as a research paper and a static web demo.
In their paper, the Stability AI researchers also propose a method for curating large amounts of video data and transforming large, cluttered video collections into suitable datasets for generative video models. This approach is designed to simplify the training of a robust foundational model for video generation.
Stable Video Diffusion is currently only available as a research version
Stable Video Diffusion is also designed to be easily adaptable to various downstream tasks, including multi-view synthesis from a single image with fine-tuning to multi-view datasets. Stability AI plans to develop an ecosystem of models that are built and extended on top of this foundation, similar to what it has done with Stable Diffusion.
Stability AI is releasing Stable Video Diffusion first as a research version on Github to gather insights and feedback on safety and quality, and to refine the model for the final release. The weights are available on HuggingFace.
This version of the model is not intended for real-world or commercial use, the company says. As with Stable Diffusion, the final model will be freely available.
In addition to the release of the research version, Stability AI has opened a waiting list for a new web experience with a text-to-video interface. This tool is intended to facilitate the practical application of Stable Video Diffusion in various fields such as advertising, education, and entertainment.
Stability AI has recently released open-source models for 3D generation, audio generation, and text generation with an LLM.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive "AI Radar" Frontier Report 6× per year, access to comments, and our complete archive.
Subscribe nowAI news without the hype
Curated by humans.
- Over 20 percent launch discount.
- Read without distractions – no Google ads.
- Access to comments and community discussions.
- Weekly AI newsletter.
- 6 times a year: “AI Radar” – deep dives on key AI topics.
- Up to 25 % off on KI Pro online events.
- Access to our full ten-year archive.
- Get the latest AI news from The Decoder.