
Dream3D is a text-to-3D model that uses Stable Diffusion, CLIP and NeRFs to create detailed 3D objects from text.
Generative AI models for 3D have been a major research focus since at least late 2021: In December 2021, Google showed Dream Fields, a generative AI model that combines OpenAI's CLIP with Neural Radiance Fields (NeRF). Through the method, 3D shapes can be synthesized from text descriptions. CLIP guides a randomly initialized NeRF network to build a matching internal representation of the text description.
Less than a year later, researchers from Concordia University in Canada demonstrated the related method CLIP-Mesh, which, however, does not use NeRFs. That same month, Google also showed Dreamfusion, a much-improved version of Dream Fields that relies on Google's large image model Imagen instead of CLIP. From Nvidia, there's GET3D, and from OpenAI, Point-E.
Dream3D combines CLIP, Stable Diffusion and NeRFs for detailed models.
A new paper by researchers at ARC Lab, Tencent PCG, ShanghaiTech University, Shanghai Engineering Research Center of Intelligent Vision and Imaging, and Shanghai Engineering Research Center of Energy Efficient and Custom AI IC now shows Dream3D, a generative text-to-3D model that combines CLIP, Stable Diffusion, a 3D generator, and NeRFs.
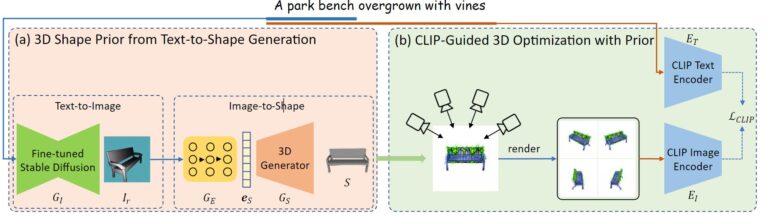
A text input is first passed to a fine-tuned Stable Diffusion model in Dream3D to synthesize a rendering-style image. This image is then converted into a 3D shape by another model.
Unlike other methods, this process uses only the portion of the text input relevant to the central shape: From "A park bench overgrown by vines", for example, only "A park bench" is used.
The resulting 3D shape is then used to initialize the NeRF, which is then optimized using CLIP guidance via the complete text input, as with other methods.
Dream3D is one of the best methods currently available
According to the team, Dream3D clearly outperforms older methods such as Dream Fields, PureCLIPNeRF or CLIP-Mesh. In fact, the NeRF renderings shown are detailed and match the text inputs.
"A car is burning." | Video: Xu, Wang, Gao et al.

"The Iron Throne in Game of Thrones." | Video: Xu, Wang, Gao et al.
"A minecraft car." | Video: Xu, Wang, Gao et al.
The advantage of initializing the NeRF with the generated 3D shape can be clearly seen. However, the team does not make a direct comparison with Google's recent Dreamfusion method.

But the use of 3D shapes as a prior for the NeRF also limits Dream3D:
Despite the strong generation capability of Stable Diffusion, we cannot constrain it to avoid generating shape images that are out of the distribution of the 3D shape generator, since Stable Diffusion is trained on a mega-scale text-image dataset while the 3D shape generator can only generate a limited amount of shapes. Besides, the quality of text-to-shape synthesis in our framework highly depends on the generation capability of the 3D generator.
From the paper.
The researchers hope to introduce better 3D priors into the system in the future, extending Dream3D's functionality to more object categories. More examples and soon the code are available on GitHub.



