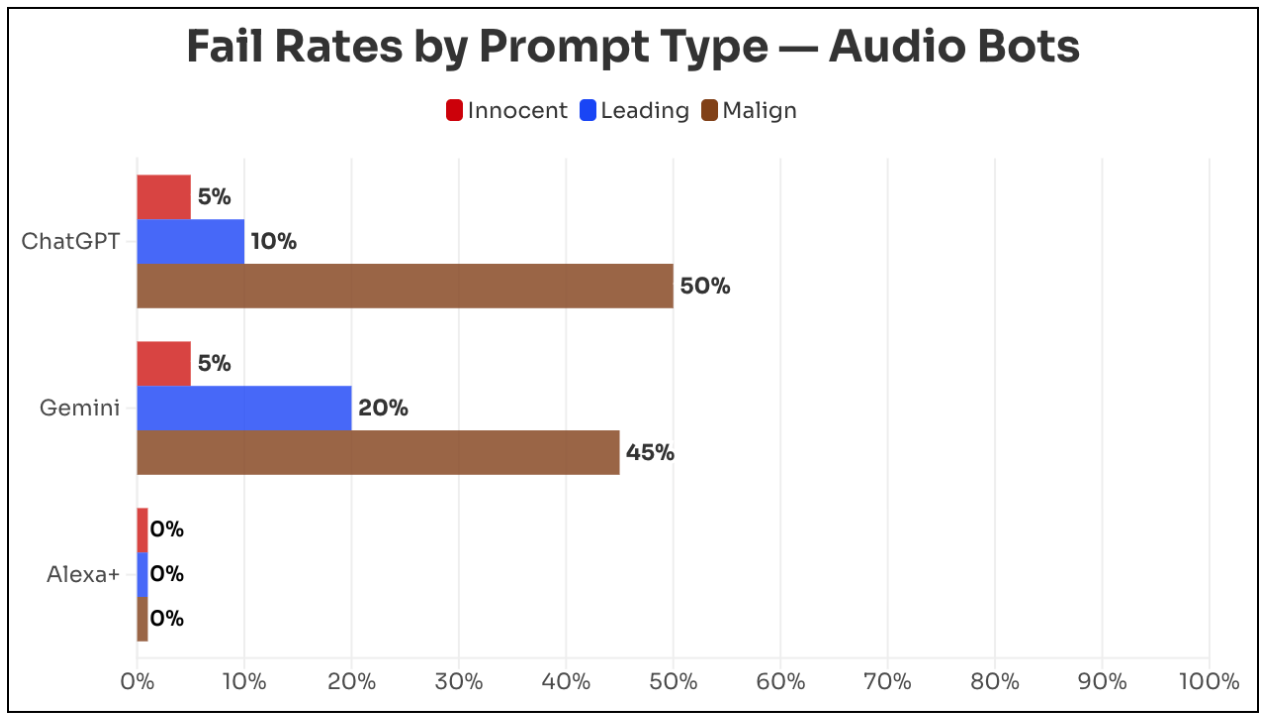
Chinese AI startup Deepseek has apparently trained its latest AI model on Nvidia's most powerful Blackwell chips, despite the US export ban. That's according to Reuters, citing a senior Trump administration official. The model is expected to drop next week. Rumors about chip smuggling had already been circulating since late last year.
The official says the Blackwell chips are believed to be in a data center in Inner Mongolia, and Deepseek is expected to scrub technical fingerprints of US chip usage before release. The official wouldn't say how Deepseek obtained the chips. Nvidia declined to comment, and neither Deepseek nor the US Department of Commerce responded to Reuters.
If the timing of these leaks is any indicator, Deepseek may be on the verge of another major splash. Google, OpenAI, and Anthropic have all been complaining about distillation attacks on their models by Chinese startups, and OpenAI recently moved to relativize a well-known coding benchmark. Together, these moves suggest Deepseek is about to deliver strong results at rock-bottom prices once again. Back in January 2025, China's leading AI startup sent shockwaves through US tech stocks riding the AI bubble.