
Q*, AGI and a briefly unemployed CEO. The dust has settled. What we know about the alleged breakthrough.
An alleged AI breakthrough by OpenAI, known as Q*, is said to have raised concerns internally about a potential threat to humanity, according to a report by Reuters. The discovery preceded the dismissal of OpenAI's former CEO, Sam Altman, and was part of a list of complaints submitted to the board by concerned researchers - or so it is said.
While the exact nature of Q* remains unclear, the internet is doing what it does best, providing everything from sober conjecture to wild speculation.
Why a Q* is necessary
Current AI technologies, such as OpenAI's ChatGPT, are capable of recognizing patterns, making inferences, and generating responses based on previously seen patterns. However, it lacks many abilities that we consider central to human intelligence, such as more or less sound reasoning. For example, a recent experiment showed that language models cannot generalize the simple formula "A is B" to "B is A".
Q* can reportedly solve some mathematical problems. Current big language models are pretty bad at math, so OpenAI uses external plugins such as Advanced Data Analytics to extend the mathematical capabilities of ChatGPT. More relevant to this story, however, is an article the company published a few months ago. In it, a team from the company managed to significantly improve the mathematical capabilities of the language models through something called "process supervision".
Process supervision is a form of reinforcement learning in which the model receives human feedback at each step of its reasoning, guiding it toward a correct answer. This is in contrast to "outcome supervision", which is used for the RLHF in ChatGPT. Process-supervised reward models (PRMs), which learn from human feedback, can be used for process supervision. OpenAI researcher John Schulman explained the central role of these processes in a presentation.
What experts say about Q*
What do PRMs have to do with Q*? They could be an important part of the system that, according to some experts, is likely to combine LLMs with planning.

In addition to language models, Q* probably relies on a non-linear method for exploring "thoughts", similar to Tree-of-Thoughts, Monte-Carlo Tree Search (MCTS), the PRMs mentioned above, and a learning algorithm like Q-learning. Nvidia's Jim Fan explains the details in a lengthy post on Twitter.com.
If the assumption is correct, Q* combines ideas such as those found in AlphaZero with language models - similar to what Microsoft researchers recently demonstrated with "Everything of Thoughts". The Microsoft team achieved impressive performance in games such as Game of 24 or 8-Puzzle - but not 100% reliability.

It is no secret that such a combination promises good results in principle: Demis Hassabis, CEO of Google Deepmind, revealed in an interview that they plan to incorporate ideas from AlphaGo into Gemini.
Test-time compute and board games
As The Information reports, another concept plays an important role: "Test-Time Compute". This is essentially the amount of time a system has to find an answer. AlphaGo is known to significantly improve its performance when given more time to search. A systematic study of this phenomenon with AI systems playing Hex has shown that training compute and inference compute of MCTS can be traded off against each other nearly one-to-one.
A similar phenomenon has been observed with the poker AI Libratus. Noam Brown, one of the authors of the paper, joined OpenAI this summer and published a post on Twitter.com about the importance of the trade-off between training time and testing time.
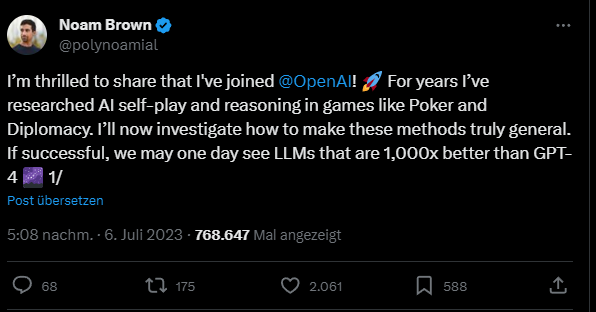
He has high hopes for the generalization of such methods beyond games.
"All those prior methods are specific to the game. But if we can discover a general version, the benefits could be huge. Yes, inference may be 1,000x slower and more costly, but what inference cost would we pay for a new cancer drug? Or for a proof of the Riemann Hypothesis?"
More information about Q*, Q-learning, and some speculation
Whatever Q* is, it's probably not AGI and may not even represent a fundamental breakthrough. But it is likely to be an example of the next generation of AI systems that are more reliable and solve some or many of the problems of today's systems like ChatGPT.
We'll have to wait for more answers, while the interpretation of the Q* rumors has already taken on a level more reminiscent of a Silicon Valley version of Q-Anon, with short quotes taken out of context, interpretation of emotional states from videos, and general AGI exegesis. There is already a suspected fake letter that portrays Q* as a dangerous AI system capable of cracking encryption.
If you want to delve deeper, you can find many articles and videos speculating about Q*. Forbes has published an in-depth article that goes into many details of the methods and concepts mentioned here. AI researcher Nathan Lambert has published one of the first blog posts, in which he hypothesizes that Q* uses Trees of Thought and PRMs.
Some relevant videos:
CBCNews - brief overview, including an interview with AI researcher Yoshua Bengio.
Yannic Kilcher: Explanation of Q-Learning
AI Explained - DeepDive and some speculations about the details of Q*.

